域模型(Domain Model)
来源:百度文库 编辑:神马文学网 时间:2024/04/29 01:40:51
域的对象模型同时包含行为和数据。
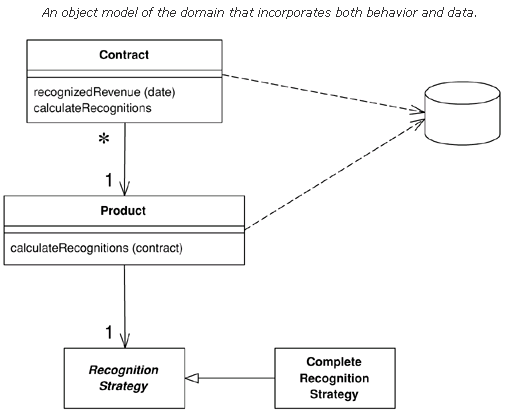
在最坏的情况下,业务逻辑可能会非常复杂。这正是对象的设计目的。域模型创建了相关关联的对象的网络,其中的每一个对象都代表了某些有用的个体,不管这个个体是大的有如一个公司,还是小的有如订单表单上的一行。
它如何工作
在应用程序中加入域模型包括插入整个由对象组成的层,这些对象是对你正在操作的业务区域进行建模。你会在其中发现模拟业务中使用的数据的类和业务模拟使用的规则的类。
面向对象域模型通常看起来与数据库模型很相似,但是也有很多不同。域模型混合数据和过程,有多值属性和复杂的关联网络,并使用继承。
结果我看到了两种风格的域模型。简单域模型看起来与数据库设计非常相似,它对于每一个数据库表基本是都有一个域对象。富域模型与数据库设计看起来有所区别,它使用了继承、策略和其它四人组模式,和相互关联的小对象复杂网络。富域模型对于更复杂逻辑是更适合的,但是,更难映射到数据库。简单域模型可以使用Active Record,而富域模型需要Data Mapper。
因为业务的行为受很多变化的支配,所以能够方便地修改、创建和测试这一层是非常重要的。因此,你会希望域模型与系统中的其它层有最小程度的耦合。你会发现很多层模式的目标就是尽可能地保持域模型系统的其它部分尽可能独立。
对于域模型你可以有很多不同的领域可以使用。最简单的情况是单用户应用程序,在其中整个对象图是从文件中读取,然后放入内存中。桌面应用程序可能以这种方式工作,但它在多层IS应用程序中是不常用的,因为有太多的对象了。将每个对象都放入内在中,将会消耗太多的内存,并且会花费太长的时间。面向对象数据库的优美就是当对象在内存和磁盘间的移动时,压缩了这个操作。
Without an OO database you have to do this yourself. Usually a session will involve pulling in an object graph of all the objects involved in it. This will certainly not be all objects and usually not all the classes. Thus, if you're looking at a set of contracts you might pull in only the products referenced by contracts within your working set. If you're just performing calculations on contracts and revenue recognition objects, you may not pull in any product objects at all. Exactly what you pull into memory is governed by your database mapping objects.
If you need the same object graph between calls to the sever, you have to save the server state somewhere, which is the subject of the section on saving server state.
对于域逻辑的关注通常是膨胀的域对象。当你在操作订单时,你会发现一些订单行为只为这个操作服务。如果你将这些职责放入订单对象,风险就是订单类会变得太大,因为在单一用例中使用的职责都放入其中了。这种关注会导致人们开始思考一些职责是否是通用的,在哪些情况下在订单类中,在什么情况下应该在特定使用类中,这个类可能是事务脚本或者就是表现本身。
分离特定使用行为的问题是它可能导致代码重复。从订单分离出来的行为是很难发现的,因此,人们可能没有发现它,而重复这个功能。重复会很快得导致复杂性和不一致性,但是我发现这种膨胀要比想象的少。假如它真的发生了,它相对地也更容易被发现,并且也不难修复。我的建议是不要分离特定使用行为。将它们都放在天生适合的对象中。当膨胀真正成为一个问题时,再修复它。
Java实现
很多关于在J2EE中开发域模型的教学资料和J2EE书籍都建议使用entity beans开发域模型。但是这种方法有一些很严重的问题,至少在目前的2.0规范中。
当你使用Container Managed Persistence(CMP)时,Entity beans是很有用的。实际上,如果没有CMP,entity beans的使用几乎没有价值。然而,CMP是面向关系映射的一种有限形式,并且它对于在富域模型中需要使用的很多模式也不支持。
Entity beans不能是re-entrant。即,如果你从一个entity bean中调用了另一个对象,那么,其它的对象(或任何它调用的其它对象)都不能回调入第一个entity bean中。富域模型经常使用re-entrancy,所以这就是一个障碍。结果,一些人说一个entity bean不应该调用另一个。这避免了re-entrancy,但这就大大削弱了使用域模型的优势。
域模型应该使用拥有fine-grained的fine-grained对象。Entity beans可以是过程的。如果你使用了拥有fine-grain接口的过程对象,你会得到极差的性能。你可以非常容易地通过使用在Domain Model中的entity beans的本地接口来解决这个问题。
为了运行entity beans你需要一个容器和一个数据库连接。这会增加生成的次数,也会增加测试的次数,因为测试需要针对一个数据库。Entity beans也是非常难以调试的。
另一个选择是使用常规Java对象,虽然导致惊奇的反应,因为有很多人认为在EJB容器中不能运行常规Java对象。我得出一个结论,人们之所以忘记了常规Java对象是因为它们没有一个好名字。这就是为什么,在2000年准备一个演讲的时候,Rebecca Parsons,Josh Mackenzie和我给了它们一个好名字:POJOs(plain old Java objects)。A POJO域模型是可以快速创建的,可以在EJB容器外测试的,它是独立于EJB的。
我的观点是如果你有一个相当适度的域逻辑,可以使用entity beans作为域模型。如果这样,你可以创建一个拥有简单数据库关联的域对象模型:每张数据库表一个entity bean。如果你拥有一个更加复杂的域逻辑,它有继承、策略和其它复杂的模式,你最好使用POJO域模型和Data Mapper。
何时使用
何时使用域模型完全取决于您系统的复杂程度。如果你有复杂的和复杂的和不断变化的业务规则,这些规则包括验证、计算,变化使你需要对象模型来处理它们。另一方面,如果你只有简单的非空检验和聚合累加计算,事务脚本是更好的选择。
如果你正在使用域模型,你的对数据交互的第一个选择就是Data Mapper。这对保持域模型独立于数据库有很有帮助的,这也是处理域模型和数据库架构发生分歧的最好的方式。
当你在使用域模型的时候,你可能想考虑使用Service Layer赋于你的域模型更清晰的API。
示例:收入确认(Java)
你会立即注意到,在这个小例子中,每一个类都包含行为和数据。甚至最小的收入计算类包括一个简单的方法,找出对象值在一个特定的日期是否是可计算的。
 class RevenueRecognition...
class RevenueRecognition...
private Money amount;
private MfDate date;
public RevenueRecognition(Money amount, MfDate date){
this.amount = amount;
this.date = date;
}
public Money getAmount(){
return amount;
}
boolean isRecognizableBy(MfDate asOf){
return asOf.after(date) || asOf.equals(date);
}
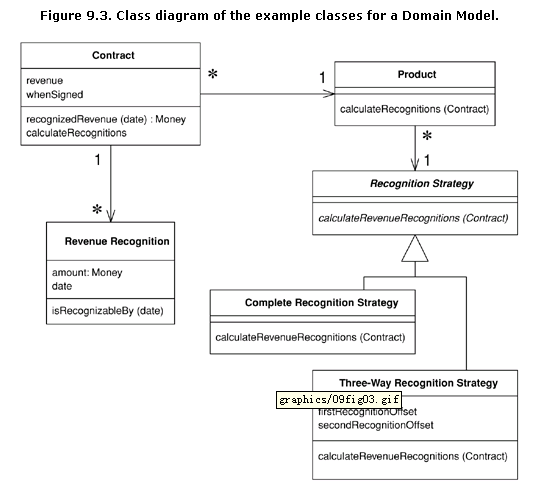
计算在某一日期计算了多少收入同时使用了合同和收入确认类。
class Contract...
private List revenueRecognitions = new ArrayList();
public Money recognizedRevenue(MfDate asOf){
Money result = Money.dollars(0);
Iterator it = revenueRecognitions.iterator();
while (it.hasNext()){
RevenueRecognition r = (RevenueRecognition) it.next();
if (r.isRecognizableBy(asOf))
result = result.add(r.getAmount());
}
return result;
}
你在域模型中最常见的事是即使在最简单的任务中也会有多个类在进行交互。这导致面向对象的程序员花费很多时间从一个类跟踪到另一个类并试图找出它们。对于这个缺陷也是有很多优点的。这会避免代码重复和减少不同对象间的耦合。
观察计算和创建这些收入确认对象更进一步展示了许多小对象。在这个例子中计算和创建由客户开始,通过产品传递到策略层次。策略模式是一个著名的面向对象模式,它允许你在一个小的类层次中组合一组操作。每个产品实例都被关联到一个计算策略实例,这个实例决定使用哪个算法计算收入。在这个例子中有两个计算策略以用于两种不同的情况。代码结构如下:
class Contract...
private Product product;
private Money revenue;
private MfDate whenSigned;
private Long id;
public Contract(Product product, Money revenue, MfDate whenSigned) ...{
this.product = product;
this.revenue = revenue;
this.whenSigned = whenSigned;
}
class Product...
private String name;
private RecognitionStrategy recognitionStrategy;
public Product(String name, RecognitionStrategy recognitionStrategy) ...{
this.name = name;
this.recognitionStrategy = recognitionStrategy;
}
public static Product newWordProcessor(String name) ...{
return new Product(name, new CompleteRecognitionStrategy());
}
public static Product newSpreadsheet(String name) ...{
return new Product(name, new ThreeWayRecognitionStrategy(60, 90));
}
public static Product newDatabase(String name) ...{
return new Product(name, new ThreeWayRecognitionStrategy(30, 60));
}
class RecognitionStrategy...
abstract void calculateRevenueRecognitions(Contract contract);
class CompleteRecognitionStrategy...
void calculateRevenueRecognitions(Contract contract) ...{
contract.addRevenueRecognition(new RevenueRecognition(contract.getRevenue(),
contract.getWhenSigned()));
}
class ThreeWayRecognitionStrategy...
private int firstRecognitionOffset;
private int secondRecognitionOffset;
public ThreeWayRecognitionStrategy(int firstRecognitionOffset,
int secondRecognitionOffset)
{
this.firstRecognitionOffset = firstRecognitionOffset;
this.secondRecognitionOffset = secondRecognitionOffset;
}
void calculateRevenueRecognitions(Contract contract) ...{
Money[] allocation = contract.getRevenue().allocate(3);
contract.addRevenueRecognition(new RevenueRecognition
(allocation[0], contract.getWhenSigned()));
contract.addRevenueRecognition(new RevenueRecognition
(allocation[1], contract.getWhenSigned().addDays(firstRecognitionOffset)));
contract.addRevenueRecognition(new RevenueRecognition
(allocation[2], contract.getWhenSigned().addDays(secondRecognitionOffset)));
}
策略的巨大价值就是提供了一个良好的扩展应用程序的插入点。加入一个新的收入确认算法包括创建一个新的子类和重载calculateRevenueRecognitions方法。这使得扩展应用程序的算法变得很容易。
当你创建产品时,你将它们与相应的策略对象关联在一起。我在我的测试代码中完成这个操作。
class Tester...
private Product word = Product.newWordProcessor("Thinking Word");
private Product calc = Product.newSpreadsheet("Thinking Calc");
private Product db = Product.newDatabase("Thinking DB");
计算确认值不需要了解策略子类。
class Contract...
public void calculateRecognitions(){
product.calculateRevenueRecognitions(this);
}
class Product...
void calculateRevenueRecognitions(Contract contract){
recognitionStrategy.calculateRevenueRecognitions(contract);
}
在最坏的情况下,业务逻辑可能会非常复杂。这正是对象的设计目的。域模型创建了相关关联的对象的网络,其中的每一个对象都代表了某些有用的个体,不管这个个体是大的有如一个公司,还是小的有如订单表单上的一行。
它如何工作
在应用程序中加入域模型包括插入整个由对象组成的层,这些对象是对你正在操作的业务区域进行建模。你会在其中发现模拟业务中使用的数据的类和业务模拟使用的规则的类。
面向对象域模型通常看起来与数据库模型很相似,但是也有很多不同。域模型混合数据和过程,有多值属性和复杂的关联网络,并使用继承。
结果我看到了两种风格的域模型。简单域模型看起来与数据库设计非常相似,它对于每一个数据库表基本是都有一个域对象。富域模型与数据库设计看起来有所区别,它使用了继承、策略和其它四人组模式,和相互关联的小对象复杂网络。富域模型对于更复杂逻辑是更适合的,但是,更难映射到数据库。简单域模型可以使用Active Record,而富域模型需要Data Mapper。
因为业务的行为受很多变化的支配,所以能够方便地修改、创建和测试这一层是非常重要的。因此,你会希望域模型与系统中的其它层有最小程度的耦合。你会发现很多层模式的目标就是尽可能地保持域模型系统的其它部分尽可能独立。
对于域模型你可以有很多不同的领域可以使用。最简单的情况是单用户应用程序,在其中整个对象图是从文件中读取,然后放入内存中。桌面应用程序可能以这种方式工作,但它在多层IS应用程序中是不常用的,因为有太多的对象了。将每个对象都放入内在中,将会消耗太多的内存,并且会花费太长的时间。面向对象数据库的优美就是当对象在内存和磁盘间的移动时,压缩了这个操作。
Without an OO database you have to do this yourself. Usually a session will involve pulling in an object graph of all the objects involved in it. This will certainly not be all objects and usually not all the classes. Thus, if you're looking at a set of contracts you might pull in only the products referenced by contracts within your working set. If you're just performing calculations on contracts and revenue recognition objects, you may not pull in any product objects at all. Exactly what you pull into memory is governed by your database mapping objects.
If you need the same object graph between calls to the sever, you have to save the server state somewhere, which is the subject of the section on saving server state.
对于域逻辑的关注通常是膨胀的域对象。当你在操作订单时,你会发现一些订单行为只为这个操作服务。如果你将这些职责放入订单对象,风险就是订单类会变得太大,因为在单一用例中使用的职责都放入其中了。这种关注会导致人们开始思考一些职责是否是通用的,在哪些情况下在订单类中,在什么情况下应该在特定使用类中,这个类可能是事务脚本或者就是表现本身。
分离特定使用行为的问题是它可能导致代码重复。从订单分离出来的行为是很难发现的,因此,人们可能没有发现它,而重复这个功能。重复会很快得导致复杂性和不一致性,但是我发现这种膨胀要比想象的少。假如它真的发生了,它相对地也更容易被发现,并且也不难修复。我的建议是不要分离特定使用行为。将它们都放在天生适合的对象中。当膨胀真正成为一个问题时,再修复它。
Java实现
很多关于在J2EE中开发域模型的教学资料和J2EE书籍都建议使用entity beans开发域模型。但是这种方法有一些很严重的问题,至少在目前的2.0规范中。
当你使用Container Managed Persistence(CMP)时,Entity beans是很有用的。实际上,如果没有CMP,entity beans的使用几乎没有价值。然而,CMP是面向关系映射的一种有限形式,并且它对于在富域模型中需要使用的很多模式也不支持。
Entity beans不能是re-entrant。即,如果你从一个entity bean中调用了另一个对象,那么,其它的对象(或任何它调用的其它对象)都不能回调入第一个entity bean中。富域模型经常使用re-entrancy,所以这就是一个障碍。结果,一些人说一个entity bean不应该调用另一个。这避免了re-entrancy,但这就大大削弱了使用域模型的优势。
域模型应该使用拥有fine-grained的fine-grained对象。Entity beans可以是过程的。如果你使用了拥有fine-grain接口的过程对象,你会得到极差的性能。你可以非常容易地通过使用在Domain Model中的entity beans的本地接口来解决这个问题。
为了运行entity beans你需要一个容器和一个数据库连接。这会增加生成的次数,也会增加测试的次数,因为测试需要针对一个数据库。Entity beans也是非常难以调试的。
另一个选择是使用常规Java对象,虽然导致惊奇的反应,因为有很多人认为在EJB容器中不能运行常规Java对象。我得出一个结论,人们之所以忘记了常规Java对象是因为它们没有一个好名字。这就是为什么,在2000年准备一个演讲的时候,Rebecca Parsons,Josh Mackenzie和我给了它们一个好名字:POJOs(plain old Java objects)。A POJO域模型是可以快速创建的,可以在EJB容器外测试的,它是独立于EJB的。
我的观点是如果你有一个相当适度的域逻辑,可以使用entity beans作为域模型。如果这样,你可以创建一个拥有简单数据库关联的域对象模型:每张数据库表一个entity bean。如果你拥有一个更加复杂的域逻辑,它有继承、策略和其它复杂的模式,你最好使用POJO域模型和Data Mapper。
何时使用
何时使用域模型完全取决于您系统的复杂程度。如果你有复杂的和复杂的和不断变化的业务规则,这些规则包括验证、计算,变化使你需要对象模型来处理它们。另一方面,如果你只有简单的非空检验和聚合累加计算,事务脚本是更好的选择。
如果你正在使用域模型,你的对数据交互的第一个选择就是Data Mapper。这对保持域模型独立于数据库有很有帮助的,这也是处理域模型和数据库架构发生分歧的最好的方式。
当你在使用域模型的时候,你可能想考虑使用Service Layer赋于你的域模型更清晰的API。
示例:收入确认(Java)
你会立即注意到,在这个小例子中,每一个类都包含行为和数据。甚至最小的收入计算类包括一个简单的方法,找出对象值在一个特定的日期是否是可计算的。
class RevenueRecognition... private Money amount; private MfDate date;public RevenueRecognition(Money amount, MfDate date){
this.amount = amount;
this.date = date;
}
public Money getAmount(){
return amount;
}
boolean isRecognizableBy(MfDate asOf){
return asOf.after(date) || asOf.equals(date);
}
计算在某一日期计算了多少收入同时使用了合同和收入确认类。
class Contract... private List revenueRecognitions = new ArrayList();public Money recognizedRevenue(MfDate asOf){
Money result = Money.dollars(0);
Iterator it = revenueRecognitions.iterator();
while (it.hasNext()){
RevenueRecognition r = (RevenueRecognition) it.next();
if (r.isRecognizableBy(asOf))
result = result.add(r.getAmount());
}
return result;
}
你在域模型中最常见的事是即使在最简单的任务中也会有多个类在进行交互。这导致面向对象的程序员花费很多时间从一个类跟踪到另一个类并试图找出它们。对于这个缺陷也是有很多优点的。这会避免代码重复和减少不同对象间的耦合。
观察计算和创建这些收入确认对象更进一步展示了许多小对象。在这个例子中计算和创建由客户开始,通过产品传递到策略层次。策略模式是一个著名的面向对象模式,它允许你在一个小的类层次中组合一组操作。每个产品实例都被关联到一个计算策略实例,这个实例决定使用哪个算法计算收入。在这个例子中有两个计算策略以用于两种不同的情况。代码结构如下:
class Contract... private Product product; private Money revenue; private MfDate whenSigned; private Long id;public Contract(Product product, Money revenue, MfDate whenSigned) ...{
this.product = product;
this.revenue = revenue;
this.whenSigned = whenSigned;
}
class Product... private String name; private RecognitionStrategy recognitionStrategy;public Product(String name, RecognitionStrategy recognitionStrategy) ...{
this.name = name;
this.recognitionStrategy = recognitionStrategy;
}
public static Product newWordProcessor(String name) ...{
return new Product(name, new CompleteRecognitionStrategy());
}
public static Product newSpreadsheet(String name) ...{
return new Product(name, new ThreeWayRecognitionStrategy(60, 90));
}
public static Product newDatabase(String name) ...{
return new Product(name, new ThreeWayRecognitionStrategy(30, 60));
}
class RecognitionStrategy... abstract void calculateRevenueRecognitions(Contract contract);class CompleteRecognitionStrategy...void calculateRevenueRecognitions(Contract contract) ...{
contract.addRevenueRecognition(new RevenueRecognition(contract.getRevenue(),
contract.getWhenSigned()));
}
class ThreeWayRecognitionStrategy... private int firstRecognitionOffset; private int secondRecognitionOffset; public ThreeWayRecognitionStrategy(int firstRecognitionOffset, int secondRecognitionOffset){
this.firstRecognitionOffset = firstRecognitionOffset;
this.secondRecognitionOffset = secondRecognitionOffset;
}
void calculateRevenueRecognitions(Contract contract) ...{
Money[] allocation = contract.getRevenue().allocate(3);
contract.addRevenueRecognition(new RevenueRecognition
(allocation[0], contract.getWhenSigned()));
contract.addRevenueRecognition(new RevenueRecognition
(allocation[1], contract.getWhenSigned().addDays(firstRecognitionOffset)));
contract.addRevenueRecognition(new RevenueRecognition
(allocation[2], contract.getWhenSigned().addDays(secondRecognitionOffset)));
}
策略的巨大价值就是提供了一个良好的扩展应用程序的插入点。加入一个新的收入确认算法包括创建一个新的子类和重载calculateRevenueRecognitions方法。这使得扩展应用程序的算法变得很容易。
当你创建产品时,你将它们与相应的策略对象关联在一起。我在我的测试代码中完成这个操作。
class Tester... private Product word = Product.newWordProcessor("Thinking Word"); private Product calc = Product.newSpreadsheet("Thinking Calc"); private Product db = Product.newDatabase("Thinking DB");计算确认值不需要了解策略子类。
class Contract...public void calculateRecognitions(){
product.calculateRevenueRecognitions(this);
}
class Product...void calculateRevenueRecognitions(Contract contract){
recognitionStrategy.calculateRevenueRecognitions(contract);
}
域模型(Domain Model)
素质模型(Competence Model)
闲谈Domain Model & Transaction Script
Dependency Injection For Rich Domain Model 1
Transaction Script 和 Domain Model--恶魔地穴
Domain-Driven / Model-Driven(转 domaindrivendesign.org)
Transparent Dependency Injection For Rich Domain Model 2
博客园 - 企业设计模式读书笔记 Domain Model
Domain Driving Model Design之总结与我的选择
CSS初学者对CSS盒模型(Box Model)的学习和理解
域控制器(Domain Controller)
JS实现不同域(Domain)之间的数据交换
飞翔的天空--实现不同域(Domain)之间的数据交换- -
域模型
blog中文翻译 商业模式(Business Model)
NBearV3教程——MVP(Model/View/Presenter)篇
Model Miy
SECI模型(野中郁次郎 & 竹内弘高)
Myhaha ? (转)心智模型
隐马尔科夫模型HMM(1)
隐马尔科夫模型HMM(2)
SECI模型(野中郁次郎 & 竹内弘高)
荷兰模型城(组图)
SECI模型(野中郁次郎 & 竹内弘高)