Bruce Zhang写在燃情岁月
来源:百度文库 编辑:神马文学网 时间:2024/04/27 22:42:36
Bruce Zhang
April 7, 2006
抽象的意义
Filed under:Prattle — bruce zhang @ 5:01 pm
我曾经听过一则笑话,说三个秀才到省城参加乡试。临行前三人都对自己能否中举惴惴不安,于是求教于街头的算命先生。算命老者的目光在这三人的脸上逡巡良久,最后徐徐伸出一个手指,就闭上眼睛不再言语,一付高深莫测的模样。三人纳闷,给了银子,带着疑惑到了省城参加考试。发榜之日,三人联袂去看成绩,得知结果后,三人齐叹,算命先生真乃神人矣!
三人考试的结果是什么呢?我们抛开具体的人不管,最后的结果不外乎如下几种:
1、全部高中;
2、一人高中;
3、两人高中;
4、全部落榜;
我们试想想,无论何种结果,算命先生的“一指禅”是否均为正解呢?
1、全部高中:此时“一个手指”代表“一个都不落榜”,或“一切人均高中”
2、一人高中:自然不言而喻
3、两人高中:此时“一个手指”代表“一人落榜”
4、全部落榜:此时“一个手指”代表“一个都不中”
算命先生确实高明,这“一指禅”确乎囊括了所有情况。为什么会是这样的情况,原因无它,盖因算命先生明白抽象的意义,他用一个手指抽象了四种可能。至于具体的实现,留给那三个秀才去慢慢琢磨吧。
抽象的意义有多大,看看算命先生就知道了。
Comments (0)
解决方案、项目、程序集、命名空间
Filed under:.Net Framework,C# Programming — bruce zhang @ 3:26 pm
《叩开C#之门》系列之一
前言:表弟想要学编程,我推荐他学习.Net和C#。这一推荐不打紧,我却承担上了指导的职责。我又出差在外,直接辅导是不行了,通过邮件也太麻烦。推荐了几本书,可惜他太菜了,总有无从下手的感觉。推及他人,在初学C#时,是否也有这样的感觉呢?所以,就有了这个系列文章。表弟是我把他带入计算机行业的,当初什么都不懂,我曾经打开计算机机箱,指点他哪里是硬盘、哪里是内存,是CPU,现在对于计算机硬件他早已可以做我师傅。希望学软件编程也能这样。
一、解决方案、项目、程序集、命名空间
初学者很容易把这些概念搞混淆。先说说项目(Project),通俗的说,一个项目可以就是你开发的一个软件。在.Net下,一个项目可以表现为多种类型,如控制台应用程序,Windows应用程序,类库(Class Library),Web应用程序,Web Service,Windows控件等等。如果经过编译,从扩展名来看,应用程序都会被编译为.exe文件,而其余的会被编译为.dll文件。既然是.exe文件,就表明它是可以被执行的,表现在程序中,这些应用程序都有一个主程序入口点,即方法Main()。而类库,Windows控件等,则没有这个入口点,所以也不能直接执行,而仅提供一些功能,给其他项目调用。
在Visual Studio.Net中,可以在“File”菜单中,选择“new”一个“Project”,来创建一个新的项目。例如创建控制台应用程序。注意在此时,Visual Studio除了建立了一个控制台项目之外,该项目同时还属于一个解决方案(Solution)。这个解决方案有什么用?如果你只需要开发一个Hello World的项目,解决方案自然毫无用处。但是,一个稍微复杂一点的软件,都需要很多模块来组成,为了体现彼此之间的层次关系,利于程序的复用,往往需要多个项目,每个项目实现不同的功能,最后将这些项目组合起来,就形成了一个完整的解决方案。形象地说,解决方案就是一个容器,在这个容器里,分成好多层,好多格,用来存放不同的项目。一个解决方案与项目是大于等于的关系。建立解决方案后,会建立一个扩展名为.sln的文件。
在解决方案里添加项目,不能再用“new”的方法,而是要在“File”菜单中,选择“Add Project”。添加的项目,可以是新项目,也可以是已经存在的项目。
程序集叫Assembly。学术的概念我不想提,通俗的角度来说,一个项目也就是一个程序集。从设计的角度来说,也可以看成是一个完整的模块(Module),或者称为是包(Package)。因此,一个程序集也可以体现为一个dll文件,或者exe文件。怎样划分程序集也是大有文章的,不过初学者暂时不用考虑它。
命名空间(namespace)是在C++里面就有的概念。引入它,主要是为了避免一个项目中,可能会存在的相同对象名的冲突。这个命名空间的定义,没有特殊的要求。不过基本上来说,为了保证其唯一性,最好是用uri的格式,例如BruceZhang.com。这个命名空间有点像我们姓名中的姓,然后每个对象的名字则是姓名中的名。如果有重复,在国外的命名中,还可以加上middle name。那么名都为“勇”的,由于姓氏不同也就分开了,或者叫张勇,或者叫赵勇。当然人的姓氏重复者居多,所以我们为命名空间取名时,尽可能的复杂一点。
有许多初学者,常常把一个项目就理解为一个命名空间。其实这两者没有绝对的联系,在项目里我们也可以定义很多不相同的命名空间。但为了用户便于使用,最好在一个项目中,其命名空间最好是一体的层次结构。在Visual Studio里,我们可以在项目中新建一个文件夹,默认情况下,该文件夹下对象的命名空间,应该是“项目的命名空间.文件夹名”。当然,我们也可以在namespace中修改它。
命名空间和程序集名,都可以在Visual Studio中设置。用鼠标右键单击项目名,就可以弹出如下对话框:
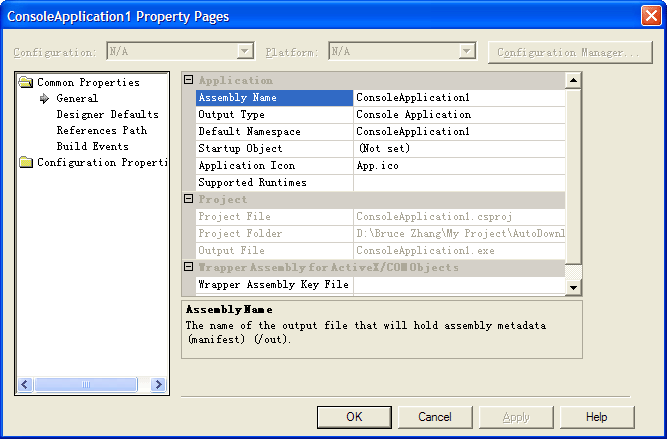
在图中,Assembly Name就是程序集名,如果经过编译,则为该项目的文件名。而Default Namespace则为默认的命名空间。在开发软件时,我们要养成良好的习惯,在建立新项目后,就将这些属性设置好。一旦设置好了Default Namespace,则以后新建的对象,其命名空间即为该设定的值。至于程序集名,如果是dll文件,建议其名最好与Default Namespace一致。
实例演练:
(一)创建控制台应用程序“Hello World!”
1、打开Visual Studio.Net,选择“File”菜单的“new”,选择“Project”;
2、选择Visual C# Projects中的“Console Application”,如图所示:
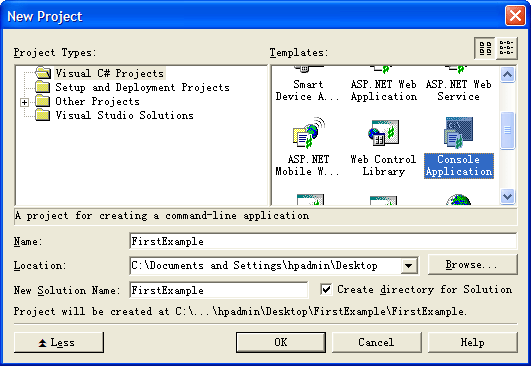
在Location中,定位你要保存的项目的路径,而名字则为“FirstExample”。该名字此时既是解决方案的名字,同时也是该项目的名字。
3、用鼠标右键单击项目名,在弹出的对话框中,将Assembly Name命名为HelloWorld,将Default Namespace命名为:BruceZhang.com.FirstExample。
4、此时Visual Studio中已经建立了一个文件,其名为Class1.cs(如果是Visual Studio 2005,则默认为Program.cs);修改该文件的文件名为HelloWorld.cs,同时修改文件中的namespace,和类名,如下:
namespace BruceZhang.com.FirstExample
{
///
/// Summary description for Class1.
///
class HelloWorld
{
///
/// The main entry point for the application.
///
[STAThread]
static void Main(string[] args)
{
//
// TODO: Add code to start application here
//
}
}
}
5、注意在HelloWorld.cs中,有一个Main()方法。这是因为我们建立的是控制台应用程序。在Main()方法中添加如下代码:
Console.WriteLine(”Hello World!”);
Console.Read();
这里的Console是一个能对控制台进行操作的类。
6、运行。
检查保存项目的路径文件夹FirstExample/bin/debug,已经存在了一个HelloWorld.exe文件。
(二)为解决方案添加一个新项目
1、在“File”菜单中,选择“Add Project”,添加“New Project”。在对话框中选择“Class Library”,名字为Printer。至于保存路径,可以放在之前建立的FirstExample文件夹下:
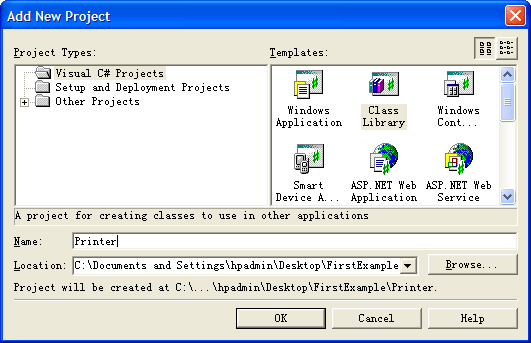
2、在Visual Studio右侧,可以看到现在有两个项目了。仍然修改新项目的名称和默认命名空间名,均为BruceZhang.com.Printer。
3、将默认建立的Class1.cs改名为MessagePrinter.cs,同时修改其代码为:
namespace BruceZhang.com.Printer
{
///
/// Summary description for Class1.
///
public class MessagePrinter
{
public MessagePrinter()
{
//
// TODO: Add constructor logic here
//
}
public static void Print(string msg)
{
Console.WriteLine(msg);
}
}
}
在MessagePrinter类中,我们注意到并没有Main()方法,因为它不是应用程序。新增加的Print()方法,能够接收一个字符串,然后在控制台中显示出来。
4、编译Printer项目。鼠标右键单击该项目名,在菜单中选择“Build”。成功编译后,找到文件夹Printer/bin/debug,可以发现有文件BruceZhang.com.Printer.dll,这就是最后形成的程序集文件。
5、关联这两个项目。我们希望是在FirstExample项目中用到Printer项目的Print()方法,前提是需要在FirstExample项目中添加对Printer项目的引用。右键单击FirstExample项目的“Reference”,选择“Add Reference”,在对话框中选择“Project”标签,找到该项目并选中,最后如图所示:
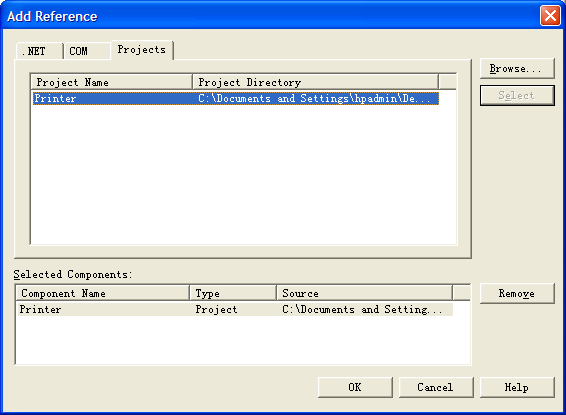
6、现在就可以在FirstExample项目中使用MessagePrinter了。首先,在命名空间中添加对它的使用(Using),然后再Main()方法中调用它,最后代码如下:
using System;
using BruceZhang.com.Printer;
namespace BruceZhang.com.FirstExample
{
///
/// Summary description for Class1.
///
class HelloWorld
{
///
/// The main entry point for the application.
///
[STAThread]
static void Main(string[] args)
{
MessagePrinter.Print(”Hello World!”);
Console.Read();
}
}
}
7、运行。结果与前一个例子一样。
在这个例子中,解决方案中就包含了两个项目,一个是控制台应用程序,一个是类库。类库提供一些基本的功能,如例子中的Print()方法。我们常常把一些共用的方法,放到类库中。这样其他的应用程序就可以去调用它。例如本例的控制台应用程序。如果新建的Windows应用程序,也需要这个功能,就可以直接引用MessagePrinter的Print()方法,而不必重复去实现。
Comments (0)
April 5, 2006
Windows Communication Foundation入门(Part One)
Filed under:WCF — bruce zhang @ 2:31 am
前言:WCF是微软基于SOA(Service Oriented Architecture)推出的.Net平台下的框架产品,它代表了软件架构设计与开发的一种发展方向,在微软的战略计划中也占有非常重要的地位。了解和掌握WCF,对于程序员特别是基于微软产品开发的程序员而言,是非常有必要的。对于WCF,笔者也是初窥门径,抱着学习的态度作这样的一个介绍。文中的内容主要参考了微软官方的文档、资料,以及众多介绍WCF的技术资料。这些资料主要都是英文,不便于国内程序员学习WCF。虽然本人才疏学浅,却愿意作这样的介绍者。由于自己仅是一个初学者,英文的功底也不够深厚,所以文中难免会有疏漏之处。同时,我也希望在文中尽量表达出自己的一些心得与见解,这就不免增加了出现错误的可能性。此外,由于WCF至今仍未有正式的版本,文中相关的技术描述以及代码会根据版本的不同而发生变化,所以我也只能尽量对此给与一定的说明。本文会是多篇文章拼凑在一起的系列,说是系列,但并没有严格的渐进关系,只是整体上希望能有一个相对全面的WCF入门介绍。此外,笔者也希望能通过此文抛砖引玉,这样也能让我的WCF学习之旅更轻松一点。
一、什么是WCF?
根据微软官方的解释,WCF(之前的版本名为“Indigo”)是使用托管代码建立和运行面向服务(Service Oriented)应用程序的统一框架。它使得开发者能够建立一个跨平台的安全、可信赖、事务性的解决方案,且能与已有系统兼容协作。WCF是微软分布式应用程序开发的集大成者,它整合了.Net平台下所有的和分布式系统有关的技术,例如.Net Remoting、ASMX、WSE和MSMQ。以通信(Communiation)范围而论,它可以跨进程、跨机器、跨子网、企业网乃至于Internet;以宿主程序而论,可以以ASP.NET,EXE,WPF,Windows Forms,NT Service,COM+作为宿主(Host)。WCF可以支持的协议包括TCP,HTTP,跨进程以及自定义,安全模式则包括SAML,Kerberos,X509,用户/密码,自定义等多种标准与模式。也就是说,在WCF框架下,开发基于SOA的分布式系统变得容易了,微软将所有与此相关的技术要素都包含在内,掌握了WCF,就相当于掌握了叩开SOA大门的钥匙。
WCF是建立在.Net Framework 2.0基础之上的,正式的版本应该会作为Windows Vista的核心部分而Release。然而,这并不代表WCF只能运行在Windows Vista下。只要安装了WinFX Runtime Components,在Windows XP和Windows 2003操作系统下,仍然可以使用。Visual Studio 2005中并没有包含WCF,但是当安装好了WinFX Runtime Components后,我们就可以在Visual Studio 2005环境下开发和创建WCF的程序了。
目前最新的WCF版本是February 2006 CTP,下载页面是:http://www.microsoft.com/downloads/details.aspx?FamilyId=F51C4D96-9AEA-474F-86D3-172BFA3B828B&displaylang=en。使用WCF需要用到一些相关的工具,如SvcUtil.exe,所以还需要下载WinFX Runtime Components的SDK,其下载页面是:http://www.microsoft.com/downloads/details.aspx?FamilyId=9BE1FC7F-0542-47F1-88DD-61E3EF88C402&displaylang=en。安装SDK可以选择网络安装或本地安装。如果是本地安装,文件大小为1.1G左右,是ISO文件。安装了SDK后,在program files目录下,有microsoft SDK目录。
WCF是微软重点介绍的产品,因此也推出了专门的官方网站(http://windowscommunication.net),该网站有最新的WCF新闻发布,以及介绍WCF的技术文档和样例代码。
二、WCF的优势
在David Chappell所撰的《Introducing Windows Communication Foundation》一文中,用了一个活鲜鲜的例子,来说明WCF的优势所在。假定我们要为一家汽车租赁公司开发一个新的应用程序,用于租车预约服务。该租车预约服务会被多种应用程序访问,包括呼叫中心(Call Center),基于J2EE的租车预约服务以及合作伙伴的应用程序(Partner Application),如图所示:
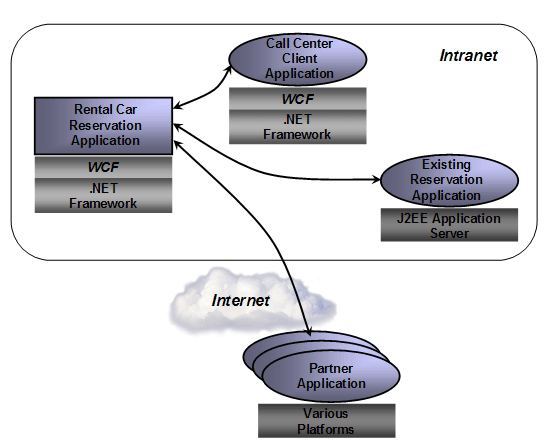
呼叫中心运行在Windows平台下,是在.Net Framework下开发的应用程序,用户为公司员工。由于该汽车租赁公司兼并了另外一家租赁公司,该公司原有的汽车预约服务应用程序是J2EE应用程序,运行在非Windows操作系统下。呼叫中心和已有的汽车预约应用程序都运行在Intranet环境下。合作伙伴的应用程序可能会运行在各种平台下,这些合作伙伴包括旅行社、航空公司等等,他们会通过Internet来访问汽车预约服务,实现对汽车的租用。
这样一个案例是一个典型的分布式应用系统。如果没有WCF,利用.Net现有的技术应该如何开发呢?
首先考虑呼叫中心,它和我们要开发的汽车预约服务一样,都是基于.Net Framework的应用程序。呼叫中心对于系统的性能要求较高,在这样的前提下,.Net Remoting是最佳的实现技术。它能够高性能的实现.Net与.Net之间的通信。
要实现与已有的J2EE汽车预约应用程序之间的通信,只有基于SOAP的Web Service可以实现此种目的,它保证了跨平台的通信;而合作伙伴由于是通过Internet来访问,利用ASP.Net Web Service,即ASMX,也是较为合理的选择,它保证了跨网络的通信。由于涉及到网络之间的通信,我们还要充分考虑通信的安全性,利用WSE(Web Service Enhancements)可以为ASMX提供安全的保证。
一个好的系统除了要保证访问和管理的安全,高性能,同时还要保证系统的可信赖性。因此,事务处理是企业应用必须考虑的因素,对于汽车预约服务而言,同样如此。在.Net中,Enterprise Service(COM+)提供了对事务的支持,其中还包括分布式事务(Distributed Transactions)。不过对于Enterprise Service而言,它仅支持有限的几种通信协议。
如果还要考虑到异步调用、脱机连接、断点连接等功能,我们还需要应用MSMQ(Microsoft Message Queuing),利用消息队列支持应用程序之间的消息传递。
如此看来,要建立一个好的汽车租赁预约服务系统,需要用到的.Net分布式技术,包括.Net Remoting、Web Service,COM+等五种技术,这既不利于开发者的开发,也加大了程序的维护难度和开发成本。正是因应于这样的缺陷,WCF才会在.Net 2.0中作为全新的分布式开发技术被微软强势推出,它整合了上述所属的分布式技术,成为了理想的分布式开发的解决之道。下图展示了WCF与之前的相关技术的比较:
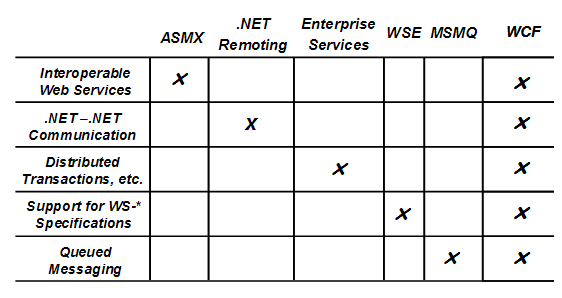
从功能的角度来看,WCF完全可以看作是ASMX,.Net Remoting,Enterprise Service,WSE,MSMQ等技术的并集。(注:这种说法仅仅是从功能的角度。事实上WCF远非简单的并集这样简单,它是真正面向服务的产品,它已经改变了通常的开发模式。)因此,对于上述汽车预约服务系统的例子,利用WCF,就可以解决包括安全、可信赖、互操作、跨平台通信等等需求。开发者再不用去分别了解.Net Remoting,ASMX等各种技术了。
概括地说,WCF具有如下的优势:
1、统一性
前面已经叙述,WCF是对于ASMX,.Net Remoting,Enterprise Service,WSE,MSMQ等技术的整合。由于WCF完全是由托管代码编写,因此开发WCF的应用程序与开发其它的.Net应用程序没有太大的区别,我们仍然可以像创建面向对象的应用程序那样,利用WCF来创建面向服务的应用程序。
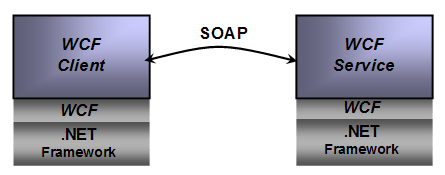
2、互操作性
由于WCF最基本的通信机制是SOAP,这就保证了系统之间的互操作性,即使是运行不同的上下文中。这种通信可以是基于.Net到.Net间的通信,如下图所示:
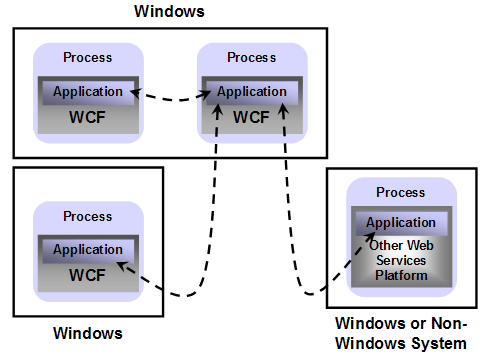
可以跨进程、跨机器甚至于跨平台的通信,只要支持标准的Web Service,例如J2EE应用服务器(如WebSphere,WebLogic)。应用程序可以运行在Windows操作系统下,也可以运行在其他的操作系统,如Sun Solaris,HP Unix,Linux等等。如下图所示:
3、安全与可信赖
WS-Security,WS-Trust和WS-SecureConversation均被添加到SOAP消息中,以用于用户认证,数据完整性验证,数据隐私等多种安全因素。
在SOAP的header中增加了WS-ReliableMessaging允许可信赖的端对端通信。而建立在WS-Coordination和WS-AtomicTransaction之上的基于SOAP格式交换的信息,则支持两阶段的事务提交(two-phase commit transactions)。
上述的多种WS-Policy在WCF中都给与了支持。对于Messaging而言,SOAP是Web Service的基本协议,它包含了消息头(header)和消息体(body)。在消息头中,定义了WS-Addressing用于定位SOAP消息的地址信息,同时还包含了MTOM(消息传输优化机制,Message Transmission Optimization Mechanism)。如图所示:

4、兼容性
WCF充分的考虑到了与旧有系统的兼容性。安装WCF并不会影响原有的技术如ASMX和.Net Remoting。即使对于WCF和ASMX而言,虽然两者都使用了SOAP,但基于WCF开发的应用程序,仍然可以直接与ASMX进行交互。
< 未完待续>
注:本部分内容主要来源于David Chappell,《Introducing Windows Communication Foundation》
Comments (0)
March 22, 2006
你注意到了吗?
Filed under:Prattle — bruce zhang @ 6:05 pm
Google提供的语言工具其实是一个好东东,用来当作辞典是绰绰有余,它还支持多种语言,真是一份免费的晚餐。
不过,你注意到了吗?如果你要利用Google的语言工具将“百度”翻译成英文,你得到的结果是“Lower”。面对搜索引擎尤其是中文的搜索引擎中最强有力的竞争对手,Google难道已经失去应有的恢宏的气度,对其竞争对手开始故意的嘲讽和贬低?也许是Google中天才们一时兴起的玩笑之作,但在我的眼中看来,却未免有失厚道了。
不要说这是百度的正宗英译,我相信从美国回来的李彦宏不会给自己公司取这样的英文名。也许是Google的老外们并不理解“百度”这两个字的含义,其实是那么的充满诗意,“众里寻她千百度,蓦然回首,那人却在灯火阑珊处。”
Comments (0)
March 6, 2006
封装变化(Part Three)
Filed under:Design & Pattern — bruce zhang @ 6:35 pm
设想这样一个需求,我们需要为自己的框架提供一个负责排序的组件。目前需要实现的是冒泡排序算法和快速排序算法,根据“面向接口编程”的思想,我们可以为这些排序算法提供一个统一的接口ISort,在这个接口中有一个方法Sort(),它能接受一个object数组参数。对数组进行排序后,返回该数组。接口的定义如下:
public interface ISort
{
void Sort(ref object[] beSorted);
}
其类图如下:
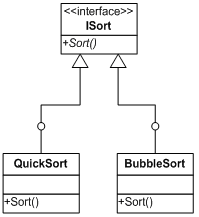
然而一般对于排序而言,排列是有顺序之分的,例如升序,或者降序,返回的结果也不相同。最简单的方法我们可以利用if语句来实现这一目的,例如在QuickSort类中:
public class QuickSort:ISort
{
private string m_SortType;
public QuickSort(string sortType)
{
m_SortType = sortType;
}
public void Sort(ref object[] beSorted)
{
if (m_SortType.ToUpper().Trim() == “ASCENDING”)
{
//执行升序的快速排序;
}
else
{
//执行降序的快速排序;
}
}
}
当然,我们也可以将string类型的SortType定义为枚举类型,减少出现错误的可能性。然而仔细阅读代码,我们可以发现这样的代码是非常僵化的,一旦需要扩展,如果要求我们增加新的排序顺序,例如字典顺序,那么我们面临的工作会非常繁重。也就是说,变化产生了。通过分析,我们发现所谓排序的顺序,恰恰是排序算法中最关键的一环,它决定了谁排列在前,谁排列在后。然而它并不属于排序算法,而是一种比较的策略,后者说是比较的行为。
如果仔细分析实现ISort接口的类,例如QuickSort类,它在实现排序算法的时候,需要对两个对象作比较。按照重构的做法,实质上我们可以在Sort方法中抽取出一个私有方法Compare(),通过返回的布尔值,决定哪个对象在前,哪个对象在后。显然,可能发生变化的是这个比较行为,利用“封装抽象”的原理,就应该为该行为建立一个专有的接口ICompare,然而分别定义实现升序、降序或者字典排序的类对象。
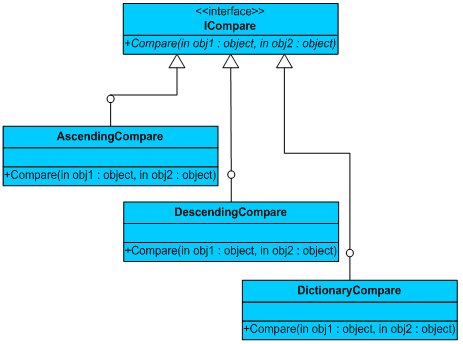
我们在每一个实现了ISort接口的类构造函数中,引入ICompare接口对象,从而建立起排序算法与比较算法的弱耦合关系(因为这个关系与抽象的ICompare接口相关),例如QuickSort类:
public class QuickSort:ISort
{
private ICompare m_Compare;
public QuickSort(ICompare compare)
{
m_Compare= compare;
}
public void Sort(ref object[] beSorted)
{
//实现略
for (int i = 0; i < beSorted.Length - 1; i++)
{
if (m_Compare.Compare(beSorted[i],beSorted[i+1))
{
//略;
}
}
//实现略
}
}
最后的类图如下:
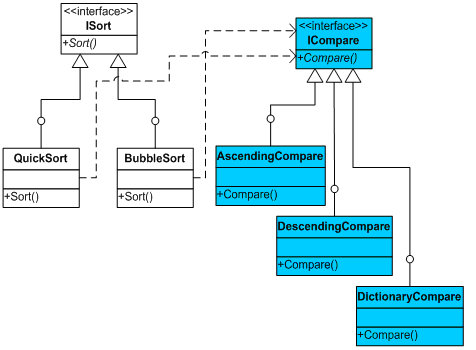
通过对比较策略的封装,以应对它的变化,显然是Stategy模式的设计。事实上,这里的排序算法也可能是变化的,例如实现二叉树排序。由于我们已经引入了“面向接口编程”的思想,我们完全可以轻易的添加一个新的类BinaryTreeSort,来实现ISort接口。对于调用方而言,ISort接口的实现,同样是一个Strategy模式。此时的类结构,完全是一个对扩展开发的状态,它完全能够适应类库调用者新需求的变化。
再以PetShop为例,在这个项目中涉及到订单的管理,例如插入订单。考虑到访问量的关系,PetShop为订单管理提供了同步和异步的方式。显然,在实际应用中只能使用这两种方式的其中一种,并由具体的应用环境所决定。那么为了应对这样一种可能会很频繁的变化,我们仍然需要利用“封装变化”的原理,建立抽象级别的对象,也就是IOrderStrategy接口:
public interface IOrderStrategy
{
void Insert(PetShop.Model.OrderInfo order);
}
然后定义两个类OrderSynchronous和OrderAsynchronous。类结构如下:
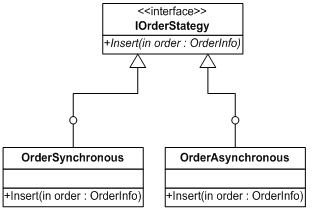
在PetShop中,由于用户随时都可能会改变插入订单的策略,因此对于业务层的订单领域对象而言,不能与具体的订单策略对象产生耦合关系。也就是说,在领域对象Order类中,不能new一个具体的订单策略对象,如下面的代码:
IOrderStrategy orderInsertStrategy = new OrderSynchronous();
在Martin Fowler的文章《IoC容器和Dependency Injection模式》中,提出了解决这类问题的办法,他称之为依赖注入。不过由于PetShop并没有使用诸如Sping.Net等IoC容器,因此解决依赖问题,通常是利用配置文件结合反射来完成的。在领域对象Order类中,是这样实现的:
public class Order
{
private static readonly IOrderStategy orderInsertStrategy = LoadInsertStrategy();
private static IOrderStrategy LoadInsertStrategy()
{
// Look up which strategy to use from config file
string path = ConfigurationManager.AppSettings[”OrderStrategyAssembly”];
string className = ConfigurationManager.AppSettings[”OrderStrategyClass”];
// Load the appropriate assembly and class
return (IOrderStrategy)Assembly.Load(path).CreateInstance(className);
}
}
在配置文件web.config中,配置如下的Section:
这其实是一种折中的Service Locator模式。将定位并创建依赖对象的逻辑直接放到对象中,在PetShop的例子中,不失为一种好方法。毕竟在这个例子中,需要依赖注入的对象并不太多。但我们也可以认为是一种无奈的妥协的办法,一旦这种依赖注入的逻辑增多,为给程序者带来一定的麻烦,这时就需要一个专门的轻量级IoC容器了。
写到这里,似乎已经脱离了“封装变化”的主题。但事实上我们需要明白,利用抽象的方式封装变化,固然是应对需求变化的王道,但它也仅仅能解除调用者与被调用者相对的耦合关系,只要还涉及到具体对象的创建,即使引入了工厂模式,但具体的工厂对象的创建仍然是必不可少的。那么,对于这样一些业已被封装变化的对象,我们还应该充分利用“依赖注入”的方式来彻底解除两者之间的耦合。
Comments (0)
February 6, 2006
封装变化(Part Two)
Filed under:Design & Pattern — bruce zhang @ 8:16 pm
考虑一个日志记录工具。目前需要提供一个方便的日志,使得客户可以轻松地完成日志的记录。该日志要求被记录到指定的文本文件中,记录的内容属于字符串类型,其值由客户提供。我们可以非常容易地定义一个日志对象:
public class Log
{
public void Write(string target, string log)
{
//实现内容;
}
}
当客户需要调用日志的功能时,可以创建日志对象,完成日志的记录:
Log log = new Log();
log.Write(“error.log”, “log”);
然而随着日志记录的频繁使用,有关日志的文件越来越多,日志的查询与管理也变得越不方便。此时,客户提出,需要改变日志的记录方式,将日志内容写入到指定的数据表中。显然,如果仍然按照前面的设计,具有较大的局限性。
现在我们回到设计之初,想象一下对于日志API的设计,需要考虑到这样的变化吗?这里存在两种设计理念,即渐进的设计和计划的设计。从本例来分析,要求设计者在设计初就考虑到日志记录方式在未来的可能变化,并不容易。再者,如果在最开始就考虑全面的设计,会产生设计上的冗余。因此,采用计划的设计固然具有一定的前瞻性,但一方面对设计者的要求过高,同时也会产生一些缺陷。那么,采用渐进的设计时,遇到需求变化时,利用重构的方法,改进现有的设计,又需要考虑未来的再一次变化吗?这是一个见仁见智的问题。对于本例而言,我们完全可以直接修改Write()方法,接受一个类型判断的参数,从而解决此问题。但这样的设计,自然要担负因为未来可能的再一次变化,而导致代码大量修改的危险,例如,我们要求日志记录到指定的Xml文件中。
所以,变化是完全可能的。在时间和技术能力允许的情况下,我更倾向于将变化对设计带来的影响降低到最低。此时,我们需要封装变化。
在封装变化之前,我们需要弄清楚究竟是什么发生了变化?从需求看,是日志记录的方式发生了变化。从这个概念分析,可能会导致两种不同的结果。一种情形是,我们将日志记录的方式视为一种行为,确切的说,是用户的一种请求。另一种情形则从对象的角度来分析,我们将各种方式的日志看作不同的对象,它们调用接口相同的行为,区别仅在于创建的是不同的对象。前者需要我们封装“用户请求的变化”,而后者需要我们封装“日志对象创建的变化”。
封装“用户请求的变化”,在这里就是封装日志记录可能的变化。也就是说,我们需要把日志记录行为抽象为一个单独的接口,然后才分别定义不同的实现。如图一所示:
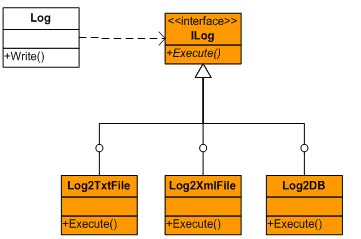
图一:封装日志记录行为的变化
如果熟悉设计模式,可以看到图一所表示的结构正是Command模式的体现。由于我们对日志记录行为进行了接口抽象,用户就可以自由地扩展日志记录的方式,只需要实现ILog接口即可。至于Log对象,则存在与ILog接口的弱依赖关系:
public class Log
{
private ILog log;
public Log(ILog log)
{
this.log = log;
}
public void Write(string target, string logValue)
{
log.Execute(target, logValue);
}
}
我们也可以通过封装“日志对象创建的变化”实现日志API的可扩展性。在这种情况下,日志会根据记录方式的不同,被定义为不同的对象。当我们需要记录日志时,就创建相应的日志对象,然后调用该对象的Write()方法,实现日志的记录。此时,可能会发生变化的是需要创建的日志对象,那么要封装这种变化,就可以定义一个抽象的工厂类,专门负责日志对象的创建,如图二所示:
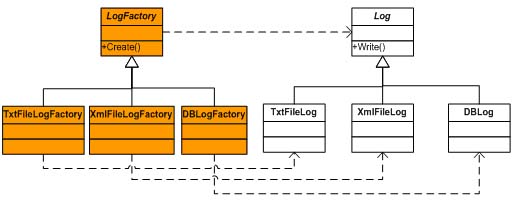
图二:封装日志对象创建的变化
图二是Factory Method模式的体现,由抽象类LogFactory专门负责Log对象的创建。如果用户需要记录相应的日志,例如要求日志记录到数据库,需要先创建具体的LogFactory对象:
LogFactory factory = new DBLogFactory();
当在应用程序中,需要记录日志,那么再通过LogFactory对象来获取新的Log对象:
Log log = factory.Create();
log.Write(“ErrorLog”, “log”);
如果用户需要改变日志记录的方式为文本文件时,仅需要修改LogFactory对象的创建即可:
LogFactory factory = new TxtFileLogFactory();
为了更好地理解“封装对象创建的变化”,我们再来看一个例子。假如,我们需要设计一个数据库组件,它能够访问微软的Sql Server数据库。根据ADO.Net的知识,我们需要使用如下的对象:
SqlConnection, SqlCommand, SqlDataAdapter等。
如果仅就Sql Server而言,在访问数据库时,我们可以直接创建这些对象:
SqlConnection connection = new SqlConnection(strConnection);
SqlCommand command = new SqlCommand(connection);
SqlDataAdapter adapter = new SqlDataAdapter();
在一个数据库组件中,充斥着如上的语句,显然是不合理的。它充满了僵化的坏味道,一旦要求支持其他数据库时,原有的设计就需要彻底的修改,这为扩展带来了困难。
那么我们来思考一下,以上的设计应该做怎样的修改?假定该数据库组件要求或者将来要求支持多种数据库,那么对于Connection,Command,DataAdapter等对象而言,就不能具体化为Sql Server的对象。也就是说,我们需要为这些对象建立一个继承的层次结构,为他们分别建立抽象的父类,或者接口。然后针对不同的数据库,定义不同的具体类,这些具体类又都继承或实现各自的父类,例如Connection对象:
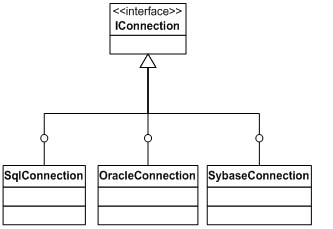
图三:Connection对象的层次结构
我为Connection对象抽象了一个统一的IConnection接口,而支持各种数据库的Connection对象都实现了IConnection接口。同样的,Command对象和DataAdapter对象也采用了相似的结构。现在,我们要创建对象的时候,可以利用多态的原理创建:
IConnection connection = new SqlConnection(strConnection);
从这个结构可以看到,根据访问的数据库的不同,对象的创建可能会发生变化。也就是说,我们需要设计的数据库组件,以现在的结构来看,仍然存在无法应对对象创建发生变化的问题。利用“封装变化”的原理,我们有必要把创建对象的责任单独抽象出来,以进行有效地封装。例如,如上的创建对象的代码,就应该由专门的对象来负责。我们仍然可以建立一个专门的抽象工厂类DBFactory,并由它负责创建Connection,Command,DataAdapter对象。至于实现该抽象类的具体类,则与目标对象的结构相同,根据数据库类型的不同,定义不同的工厂类,类图如图四所示:
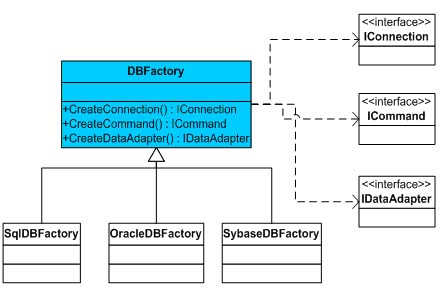
图四:DBFactory的类图
图四是一个典型的Abstract Factory模式的体现。类DBFactory中的各个方法均为abstract方法,所以我们也可以用接口来代替该类的定义。继承DBFactory类的各个具体类,则创建相对应的数据库类型的对象。以SqlDBFactory类为例,创建各自对象的代码如下:
public class SqlDBFactory: DBFactory
{
public override IConnection CreateConnection(string strConnection)
{
return new SqlConnection(strConnection);
}
public override ICommand CreateCommand(IConnection connection)
{
return new SqlCommand(connection);
}
public override IDataAdapter CreateDataAdapter()
{
return new SqlDataAdapter();
}
}
现在要创建访问Sql Server数据库的相关对象,就可以利用工厂类来获得。首先,我们可以在程序的初始化部分创建工厂对象:
DBFactory factory = new SqlDBFactory();
然后利用该工厂对象创建相应的Connection,Command等对象:
IConnection connection = factory.CreateConnection(strConnection);
ICommand command = factory.CreateCommand(connection);
由于我们利用了封装变化的原理,建立了专门的工厂类,以封装对象创建的变化。可以看到,当我们引入工厂类后,Connection,Command等对象的创建语句中,已经成功地消除了其与具体的数据库类型相依赖的关系。在如上的代码中,并未出现Sql之类的具体类型,如SqlConnection、SqlCommand等。也就是说,现在创建对象的方式是完全抽象的,是与具体实现无关的。无论是访问何种数据库,都与这几行代码无关。至于涉及到的数据库类型的变化,则全部抽象到DBFactory抽象类中了。需要更改访问数据库的类型,我们也只需要修改创建工厂对象的那一行代码,例如将Sql Server类型修改为Oracle类型:
DBFactory factory = new OracleDBFactory();
很显然,这样的方式提高了数据库组件的可扩展性。我们将可能发生变化的部分封装起来,放到程序固定的部分,例如初始化部分,或者作为全局变量,更可以将这些可能发生变化的地方,放到配置文件中,通过读取配置文件的值,创建相对应的对象。如此一来,不需要修改代码,也不需要重新编译,仅仅是修改xml文件,就能实现数据库类型的改变。例如,我们创建如下的配置文件:
创建工厂对象的代码则相应修改如下:
string factoryName = ConfigurationSettings.AppSettings[“db”].ToString();
//DBLib为数据库组件的程序集:
DBFactory factory = (DBFactory)Activator.CreateInstance(“DBLib”,factoryName).Unwrap();
为数据库组件的程序集:当我们需要将访问的数据库类型修改为Oracle数据库时,只需要将配置文件中的Value值修改为“OracleDBFactory”即可。这种结构具有很好的可扩展性,较好地解决了未来可能发生的需求变化所带来的问题。
Comments (0)
January 19, 2006
封装变化(Part One)
Filed under:Design & Pattern — bruce zhang @ 8:16 pm
软件设计最大的敌人,就是应付需求不断的变化。变化有时候是无穷尽的,于是项目开发就在反复的修改、更新中无限期地延迟交付的日期。变化如悬在头顶的达摩克斯之剑,令许多软件工程专家一筹莫展。正如无法找到解决软件开发的“银弹”,要彻底将变化扼杀在摇篮之中,看来也是不可能完成的任务。那么,积极地面对“变化”,方才是可取的态度。于是,极限编程(XP)的倡导者与布道者Kent Beck提出要“拥抱变化”,从软件工程方法的角度,提出了应对“变化”的解决方案。而本文则试图从软件设计方法的角度,来探讨如何在软件设计过程中,解决未来可能的变化,其方法就是——封装变化。
设计模式是“封装变化”方法的最佳阐释。无论是创建型模式、结构型模式还是行为型模式,归根结底都是寻找软件中可能存在的“变化”,然后利用抽象的方式对这些变化进行封装。由于抽象没有具体的实现,就代表了一种无限的可能性,使得其扩展成为了可能。所以,我们在设计之初,除了要实现需求所设定的用例之外,还需要标定可能或已经存在的“变化”之处。封装变化,最重要的一点就是发现变化,或者说是寻找变化。
GOF对设计模式的分类,已经彰显了“封装变化”的内涵与精髓。创建型模式的目的就是封装对象创建的变化。例如Factory Method模式和Abstract Factory模式,建立了专门的抽象的工厂类,以此来封装未来对象的创建所引起的可能变化。而Builder模式则是对对象内部的创建进行封装,由于细节对抽象的可替换性,使得将来面对对象内部创建方式的变化,可以灵活的进行扩展或替换。
至于结构型模式,它关注的是对象之间组合的方式。本质上说,如果对象结构可能存在变化,主要在于其依赖关系的改变。当然对于结构型模式来说,处理变化的方式不仅仅是封装与抽象那么简单,还要合理地利用继承与聚合的方法,灵活地表达对象之间的依赖关系。例如Decorator模式,描述的就是对象间可能存在的多种组合方式,这种组合方式是一种装饰者与被装饰者之间的关系,因此封装这种组合方式,抽象出专门的装饰对象显然正是“封装变化”的体现。同样地,Bridge模式封装的则是对象实现的依赖关系,而Composite模式所要解决的则是对象间存在的递归关系。
行为型模式关注的是对象的行为。行为型模式需要做的是对变化的行为进行抽象,通过封装以达到整个架构的可扩展性。例如策略模式,就是将可能存在变化的策略或算法抽象为一个独立的接口或抽象类,以实现策略扩展的目的。Command模式、State模式、Vistor模式、Iterator模式概莫如是。或者封装一个请求(Command模式),或者封装一种状态(State模式),或者封装“访问”的方式(Visitor模式),或者封装“遍历”算法(Iterator模式)。而这些所要封装的行为,恰恰是软件架构中最不稳定的部分,其扩展的可能性也最大。将这些行为封装起来,利用抽象的特性,就提供了扩展的可能。
利用设计模式,通过封装变化的方法,可以最大限度的保证软件的可扩展性。面对纷繁复杂的需求变化,虽然不可能完全解决因为变化带来的可怕梦魇,然而,如能在设计之初预见某些变化,仍有可能在一定程度上避免未来存在的变化为软件架构带来的灾难性伤害。从此点看,虽然没有“银弹”,但从软件设计方法的角度来看,设计模式也是一枚不错的“铜弹”了。
Comments (0)
December 16, 2005
Switch语句,僵化的毒药
Filed under:Design & Pattern — bruce zhang @ 9:29 pm
在《Head First Design Patterns》一书中,用了大量的代码实例来讲解设计模式。该书的代码是用Java写的,Mark McFadden将其改作了C#版本的代码,下载地址:HeadFirstDesignPatternCSharp。在书中讲解Abstract Factory模式时,用PizzaStore来举例说明。这个例子非常生动,也有利于读者对Abstract Factory的理解。其中,PizzaStore的类图结构如下:
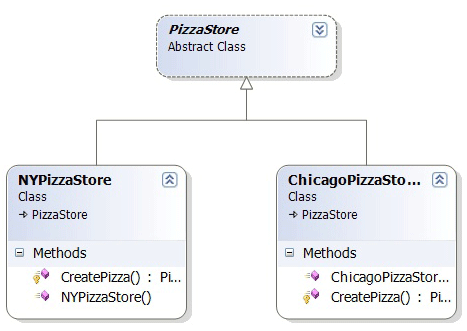
继承PizzaStore抽象类的子类NYPizzaStore和ChicagoPizzStore各自override了CreatePizza()方法,根据传入的字符串type,创建不同类型的Pizza。该方法在基类PizzaStore中被OrderPizza()方法调用。OrderPizza()方法的代码如下:
public Pizza OrderPizza(string type)
{
Pizza pizza;
pizza = CreatePizza(type);
pizza.Prepare();
pizza.Bake();
pizza.Cut();
pizza.Box();
return pizza;
}
CreatePizza()方法为虚方法,在子类NYPizzaStore中,override该方法如下:
protected override Pizza CreatePizza(string type)
{
Pizza pizza = null;
IPizzaIngredientFactory ingredientFactory = new NYPizzaIngredientFactory();
switch (type)
{
case “cheese”:
pizza = new CheesePizza(ingredientFactory);
pizza.Name = “New York Style Cheese Pizza”;
break;
case “clam”:
pizza = new ClamPizza(ingredientFactory);
pizza.Name = “New York Style Clam Pizza”;
break;
case “pepperoni”:
pizza = new PepperoniPizza(ingredientFactory);
pizza.Name = “New York Style Pepperoni Pizza”;
break;
}
return pizza;
}
然而在该方法中,却出现了讨厌的switch语句。switch语句虽然在条件判断中会被经常用到,但在本例中却不利于程序的扩展。例如增加一种Pizza,就必须修改各个PizzaStore的子类。毫无疑问,是switch语句导致了最终整个程序的僵化。那么,如何消除switch语句呢?仔细分析程序的结构,Pizza根据类型而分为CheesePizza, ClamPizza, PepperoniPizza,同时又根据PizzaStore的不同分为New York和Chicago的Pizza。这是一种类型的组合,如何对每种类型都创建一个类,这样需要定义的类对象太多。作者在解决这个问题时,是在各种类型的Pizza类的构造函数中,引入了IPizzaIngredientFactory,该工厂负责Pizza各种配料的制作(PizzaStore的不同,主要是有这些配料的制作方式不一样),这种方式将Factory模式和Bridge模式结合,保证了程序的可扩展。
在CreatePizza方法中,既然是根据type来创建不同的Pizza,也就说这个方法的责任就是用来创建Pizza的。那么,我们完全可以为程序再引入一个工厂类PizzaFactory(也可以用接口),用它来专门负责各种Pizza的创建,类图如下:
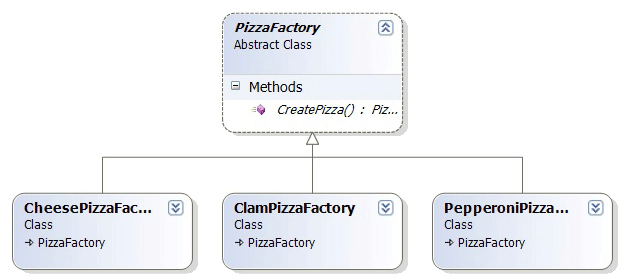
在这些创建Pizza的方法中,还需要引入IPizzaIngredientFactory对象,以决定Pizza是New York Style,还是Chicago Style。代码如下:
public abstract class PizzaFactory
{
public abstract Pizza CreatePizza(IPizzaIngredientFactory ingredientFactory);
}
public class CheesePizzaFactory : PizzaFactory
{
public override Pizza CreatePizza(IPizzaIngredientFactory ingredientFactory)
{
return new CheesePizza(ingredientFactory);
}
}
在引入该工厂类后,我们就可以对NYPizzaStore和ChicagoPizzaStore类的CreatePizza()方法做如下的修改:
public class NYPizzaStore : PizzaStore
{
protected override Pizza CreatePizza(PizzaFactory pizzaFactory)
{
IPizzaIngredientFactory ingredientFactory = new NYPizzaIngredientFactory();
return pizzaFactory.CreatePizza(ingredientFactory);
}
}
public class ChicagoPizzaStore : PizzaStore
{
protected override Pizza CreatePizza(PizzaFactory pizzaFactory)
{
IPizzaIngredientFactory ingredientFactory = new ChicagoPizzaIngredientFactory();
return pizzaFactory.CreatePizza(ingredientFactory);
}
}
在引入该工厂后,不仅消除了讨厌的switch语句,同时也使得CreatePizza()方法更加简单。要Create不同的Pizza,只需要将不同Pizza的Factory对象传递给CreatePizza()方法就可以了。相应的, PizzaStore抽象类的OrderPizza()方法中的string类型参数,也需要修改为PizzaFactory类型:
public Pizza OrderPizza(PizzaFactory pizzaFactory)
{
Pizza pizza;
pizza = CreatePizza(pizzaFactory);
pizza.Prepare();
pizza.Bake();
pizza.Cut();
pizza.Box();
return pizza;
}
当我们增加新类型的Pizza时,仅需要在PizzaFactory中增加相应的Factory类,而PizzaStore的所有子类,都不需要做任何修改。显然这种做法,更有利于程序的扩展。
Comments (0)
November 16, 2005
面向对象思想
Filed under:Design & Pattern — bruce zhang @ 10:01 pm
面向对象思想为软件设计与开发赋予了哲学的意义。在哲学的世界里,小至沙粒微尘,大至日月星辰乃至宇宙,均可视为单独的个体对象而存在。如果以哲学的目光凝视程序的世界,又何尝不是如此?一个用户,一种销售策略,一条消息,或是某种算法,一个Web的网页,面向对象思想均将其看作为一种对象。而每一种对象,都有其单独的生命周期,谁来创建它,谁来销毁它,它的内在属性,表现行为,以及它与外界之间的关系和集合,无不具有某种哲学的意味。我们在定义对象时,就好比是在描述一个活生生的事物,需要定义该对象的自然属性和社会属性,限定它的内涵与外延,勾勒出该对象的社会关系。而对于抽象、多态与封装,则是一种形而上学的概念,它将面向对象技术推向为思想的境界。
因此,我们在运用面向对象思想来定义对象时,就必须从思想的高度上俯瞰它,同时又必须结合现实来描述它。两者之间并没有绝对的矛盾。
所谓思想的高度,就要求我们必须理解所谓面向对象思想的精髓,并通过运用诸如设计模式、对象法则等知识,并从软件架构的角度出发,高屋建瓴地勾勒出整个软件结构的全貌。说得玄一些,就颇有几分“超然物外”的感觉。
所谓结合现实,也即是说对象离不开其依存的环境,毕竟软件设计不可能达到完全抽象的境界。从软件工程的角度来看,就是在设计时,需结合客户的需求、具体的业务来综合考虑。怎么界定对象的边界?对象的属性和行为是什么?哪些需要封装,而哪一些又需要暴露接口?有时候,业务才能决定设计的一切,如果纯为设计而设计,只能是空中楼阁,并不能搭建出扎实的建筑来。
Comments (0)
基于消息与.Net Remoting的分布式处理架构
Filed under:.Net Framework,Design & Pattern,.Net Remoting — bruce zhang @ 9:45 pm
分布式处理在大型企业应用系统中,最大的优势是将负载分布。通过多台服务器处理多个任务,以优化整个系统的处理能力和运行效率。分布式处理的技术核心是完成服务与服务之间、服务端与客户端之间的通信。在.Net 1.1中,可以利用Web Service或者.Net Remoting来实现服务进程之间的通信。本文将介绍一种基于消息的分布式处理架构,利用了.Net Remoting技术,并参考了CORBA Naming Service的处理方式,且定义了一套消息体制,来实现分布式处理。
示例代码:ServiceManager.rar
一、消息的定义
要实现进程间的通信,则通信内容的载体——消息,就必须在服务两端具有统一的消息标准定义。从通信的角度来看,消息可以分为两类:Request Messge和Reply Message。为简便起见,这两类消息可以采用同样的结构。
消息的主体包括ID,Name和Body,我们可以定义如下的接口方法,来获得消息主体的相关属性:
public interface IMessage:ICloneable
{
IMessageItemSequence GetMessageBody();
string GetMessageID();
string GetMessageName();
void SetMessageBody(IMessageItemSequence aMessageBody);
void SetMessageID(string aID);
void SetMessageName(string aName);
}
消息主体类Message实现了IMessage接口。在该类中,消息体Body为IMessageItemSequence类型。这个类型用于Get和Set消息的内容:Value和Item:
public interface IMessageItemSequence:ICloneable
{
IMessageItem GetItem(string aName);
void SetItem(string aName,IMessageItem aMessageItem);
string GetValue(string aName);
void SetValue(string aName,string aValue);
}
Value为string类型,并利用HashTable来存储Key和Value的键值对。而Item则为IMessageItem类型,同样的在IMessageItemSequence的实现类中,利用HashTable存储了Key和Item的键值对。
IMessageItem支持了消息体的嵌套。它包含了两部分:SubValue和SubItem。实现的方式和IMessageItemSequence相似。定义这样的嵌套结构,使得消息的扩展成为可能。一般的结构如下:
IMessage——Name
——ID
——Body(IMessageItemSequence)
——Value
——Item(IMessageItem)
——SubValue
——SubItem(IMessageItem)
——……
各个消息对象之间的关系如下:
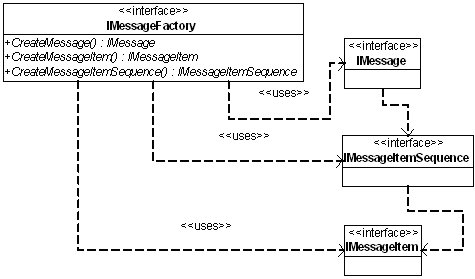
在实现服务进程通信之前,我们必须定义好各个服务或各个业务的消息格式。通过消息体的方法在服务的一端设置消息的值,然后发送,并在服务的另一端获得这些值。例如发送消息端定义如下的消息体:
IMessageFactory factory = new MessageFactory();
IMessageItemSequence body = factory.CreateMessageItemSequence();
body.SetValue(”name1″,”value1″);
body.SetValue(”name2″,”value2″);
IMessageItem item = factory.CreateMessageItem();
item.SetSubValue(”subname1″,”subvalue1″);
item.SetSubValue(”subname2″,”subvalue2″);
IMessageItem subItem1 = factory.CreateMessageItem();
subItem1.SetSubValue(”subsubname11″,”subsubvalue11″);
subItem1.SetSubValue(”subsubname12″,”subsubvalue12″);
IMessageItem subItem2 = factory.CreateMessageItem();
subItem1.SetSubValue(”subsubname21″,”subsubvalue21″);
subItem1.SetSubValue(”subsubname22″,”subsubvalue22″);
item.SetSubItem(”subitem1″,subItem1);
item.SetSubItem(”subitem2″,subItem2);
body.SetItem(”item”,item);
//Send Request Message
MyServiceClient service = new MyServiceClient(”Client”);
IMessageItemSequence reply = service.SendRequest(”TestService”,”Test1″,body);
在接收消息端就可以通过获得body的消息体内容,进行相关业务的处理。
二、.Net Remoting服务
在.Net中要实现进程间的通信,主要是应用Remoting技术。根据前面对消息的定义可知,实际上服务的实现,可以认为是对消息的处理。因此,我们可以对服务进行抽象,定义接口IService:
public interface IService
{
IMessage Execute(IMessage aMessage);
}
Execute()方法接受一条Request Message,对其进行处理后,返回一条Reply Message。在整个分布式处理架构中,可以认为所有的服务均实现该接口。但受到Remoting技术的限制,如果要实现服务,则该服务类必须继承自MarshalByRefObject,同时必须在服务端被Marshal。随着服务类的增多,必然要在服务两端都要对这些服务的信息进行管理,这加大了系统实现的难度与管理的开销。如果我们从另外一个角度来分析服务的性质,基于消息处理而言,所有服务均是对Request Message的处理。我们完全可以定义一个Request服务负责此消息的处理。
然而,Request服务处理消息的方式虽然一致,但毕竟服务实现的业务,即对消息处理的具体实现,却是不相同的。对我们要实现的服务,可以分为两大类:业务服务与Request服务。实现的过程为:首先,具体的业务服务向Request服务发出Request请求,Request服务侦听到该请求,然后交由其侦听的服务来具体处理。
业务服务均具有发出Request请求的能力,且这些服务均被Request服务所侦听,因此我们可以为业务服务抽象出接口IListenService:
public interface IListenService
{
IMessage OnRequest(IMessage aMessage);
}
Request服务实现了IService接口,并包含IListenService类型对象的委派,以执行OnRequest()方法:
public class RequestListener:MarshalByRefObject,IService
{
public RequestListener(IListenService listenService)
{
m_ListenService = listenService;
}
private IListenService m_ListenService;
#region IService Members
public IMessage Execute(IMessage aMessage)
{
return this.m_ListenService.OnRequest(aMessage);
}
#endregion
public override object InitializeLifetimeService()
{
return null;
}
}
在RequestListener服务中,继承了MarshalByRefObject类,同时实现了IService接口。通过该类的构造函数,接收IListService对象。
由于Request消息均由Request服务即RequestListener处理,因此,业务服务的类均应包含一个RequestListener的委派,唯一的区别是其服务名不相同。业务服务类实现IListenService接口,但不需要继承MarshalByRefObject,因为被Marshal的是该业务服务内部的RequestListener对象,而非业务服务本身:
public abstract class Service:IListenService
{
public Service(string serviceName)
{
m_ServiceName = serviceName;
m_RequestListener = new RequestListener(this);
}
#region IListenService Members
public IMessage OnRequest(IMessage aMessage)
{
//……
}
#endregion
private string m_ServiceName;
private RequestListener m_RequestListener;
}
Service类是一个抽象类,所有的业务服务均继承自该类。最后的服务架构如下:
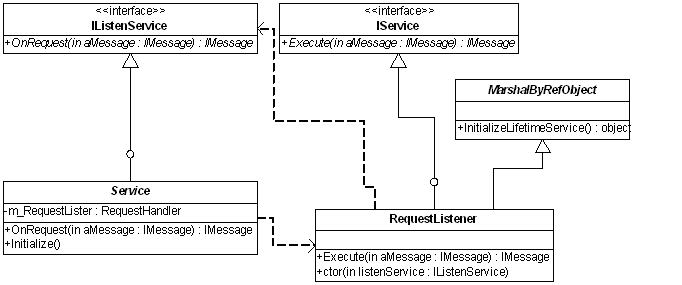
我们还需要在Service类中定义发送Request消息的行为,通过它,才能使业务服务被RequestListener所侦听。
public IMessageItemSequence SendRequest(string aServiceName,string aMessageName,IMessageItemSequence aMessageBody)
{
IMessage message = m_Factory.CreateMessage();
message.SetMessageName(aMessageName);
message.SetMessageID(”");
message.SetMessageBody(aMessageBody);
IService service = FindService(aServiceName);
IMessageItemSequence replyBody = m_Factory.CreateMessageItemSequence();
if (service != null)
{
IMessage replyMessage = service.Execute(message);
replyBody = replyMessage.GetMessageBody();
}
else
{
replyBody.SetValue(”result”,”Failure”);
}
return replyBody;
}
注意SendRequest()方法的定义,其参数包括服务名,消息名和被发送的消息主体。而在实现中最关键的一点是FindService()方法。我们要查找的服务正是与之对应的RequestListener服务。不过,在此之前,我们还需要先将服务Marshal:
public void Initialize()
{
RemotingServices.Marshal(this.m_RequestListener,this.m_ServiceName + “.RequestListener”);
}
我们Marshal的对象,是业务服务中的Request服务对象m_RequestListener,这个对象在Service的构造函数中被实例化:
m_RequestListener = new RequestListener(this);
注意,在实例化的时候是将this作为IListenService对象传递给RequestListener。因此,此时被Marshal的服务对象,保留了业务服务本身即Service的指引。可以看出,在Service和RequestListener之间,采用了“双重委派”的机制。
通过调用Initialize()方法,初始化了一个服务对象,其类型为RequestListener(或IService),其服务名为:Service的服务名 + “.RequestListener”。而该服务正是我们在SendRequest()方法中要查找的Service:
IService service = FindService(aServiceName);
下面我们来看看FindService()方法的实现:
protected IService FindService(string aServiceName)
{
lock (this.m_Services)
{
IService service = (IService)m_Services[aServiceName];
if (service != null)
{
return service;
}
else
{
IService tmpService = GetService(aServiceName);
AddService(aServiceName,tmpService);
return tmpService;
}
}
}
可以看到,这个服务是被添加到m_Service对象中,该对象为SortedList类型,服务名为Key,IService对象为Value。如果没有找到,则通过私有方法GetService()来获得:
private IService GetService(string aServiceName)
{
IService service = (IService)Activator.GetObject(typeof(RequestListener),
“tcp://localhost:9090/” + aServiceName + “.RequestListener”);
return service;
}
在这里,Channel、IP、Port应该从配置文件中获取,为简便起见,这里直接赋为常量。
再分析SendRequest方法,在找到对应的服务后,执行了IService的Execute()方法。此时的IService为RequestListener,而从前面对RequestListener的定义可知,Execute()方法执行的其实是其侦听的业务服务的OnRequest()方法。
我们可以定义一个具体的业务服务类,来分析整个消息传递的过程。该类继承于Service抽象类:
public class MyService:Service
{
public MyService(string aServiceName):base(aServiceName)
{}
}
假设把进程分为服务端和客户端,那么对消息处理的步骤如下:
1、 在客户端调用MyService的SendRequest()方法发送Request消息;
2、 查找被Marshal的服务,即RequestListener对象,此时该对象应包含对应的业务服务对象MyService;
3、 在服务端调用RequestListener的Execute()方法。该方法则调用业务服务MyService的OnRequest()方法。
在这些步骤中,除了第一步在客户端执行外,其他的步骤均是在服务端进行。
三、业务服务对于消息的处理
前面实现的服务架构,已经较为完整地实现了分布式的服务处理。但目前的实现,并未体现对消息的处理。我认为,对消息的处理,等价与具体的业务处理。这些业务逻辑必然是在服务端完成。每个服务可能会处理单个业务,也可能会处理多个业务。并且,服务与服务之间仍然存在通信,某个服务在处理业务时,可能需要另一个服务的业务行为。也就是说,每一种类的消息,处理的方式均有所不同,而这些消息的唯一标识,则是在SendRequest()方法已经有所体现的aMessageName。
虽然,处理的消息不同,所需要的服务不同,但是根据我们对消息的定义,我们仍然可以将这些消息处理机制抽象为一个统一的格式;在.Net中,体现这种机制的莫过于委托delegate。我们可以定义这样的一个委托:
public delegate void RequestHandler(string aMessageName,IMessageItemSequence aMessageBody,ref IMessageItemSequence aReplyMessageBody);
在RequestHandler委托中,它代表了这样一族方法:接收三个入参,aMessageName,aMessageBody,aReplyMessageBody,返回值为void。其中,aMessageName代表了消息名,它是消息的唯一标识;aMessageBody是待处理消息的主体,业务所需要的所有数据都存储在aMessageBody对象中。aReplyMessageBody是一个引用对象,它存储了消息处理后的返回结果,通常情况下,我们可以用< "result","Success">或< "result", "Failure">来代表处理的结果是成功还是失败。
这些委托均在服务初始化时被添加到服务类的SortedList对象中,键值为aMessageName。所以我们可以在抽象类中定义如下方法:
protected abstract void AddRequestHandlers();
protected void AddRequestHandler(string aMessageName,RequestHandler handler)
{
lock (this.m_EventHandlers)
{
if (!this.m_EventHandlers.Contains(aMessageName))
{
this.m_EventHandlers.Add(aMessageName,handler);
}
}
}
protected RequestHandler FindRequestHandler(string aMessageName)
{
lock (this.m_EventHandlers)
{
RequestHandler handler = (RequestHandler)m_EventHandlers[aMessageName];
return handler;
}
}
AddRequestHandler()用于添加委托对象与aMessageName的键值对,而FindRequestHandler()方法用于查找该委托对象。而抽象方法AddRequestHandlers()则留给Service的子类实现,简单的实现如MyService的AddRequestHandlers()方法:
public class MyService:Service
{
public MyService(string aServiceName):base(aServiceName)
{}
protected override void AddRequestHandlers()
{
this.AddRequestHandler(”Test1″,new RequestHandler(Test1));
this.AddRequestHandler(”Test2″,new RequestHandler(Test2));
}
private void Test1(string aMessageName,IMessageItemSequence aMessageBody,ref IMessageItemSequence aReplyMessageBody)
{
Console.WriteLine(”MessageName:{0}\n”,aMessageName);
Console.WriteLine(”MessageBody:{0}\n”,aMessageBody);
aReplyMessageBody.SetValue(”result”,”Success”);
}
private void Test2(string aMessageName,IMessageItemSequence aMessageBody,ref IMessageItemSequence aReplyMessageBody)
{
Console.WriteLine(”Test2″ + aMessageBody.ToString());
}
}
Test1和Test2方法均为匹配RequestHandler委托签名的方法,然后在AddRequestHandlers()方法中,通过调用AddRequestHandler()方法将这些方法与MessageName对应起来,添加到m_EventHandlers中。
需要注意的是,本文为了简要的说明这种处理方式,所以简化了Test1和Test2方法的实现。而在实际开发中,它们才是实现具体业务的重要方法。而利用这种方式,则解除了服务之间依赖的耦合度,我们随时可以为服务添加新的业务逻辑,也可以方便的增加服务。
通过这样的设计,Service的OnRequest()方法的最终实现如下所示:
public IMessage OnRequest(IMessage aMessage)
{
string messageName = aMessage.GetMessageName();
string messageID = aMessage.GetMessageID();
IMessage message = m_Factory.CreateMessage();
IMessageItemSequence replyMessage = m_Factory.CreateMessageItemSequence();
RequestHandler handler = FindRequestHandler(messageName);
handler(messageName,aMessage.GetMessageBody(),ref replyMessage);
message.SetMessageName(messageName);
message.SetMessageID(messageID);
message.SetMessageBody(replyMessage);
return message;
}
利用这种方式,我们可以非常方便的实现服务间通信,以及客户端与服务端间的通信。例如,我们分别在服务端定义MyService(如前所示)和TestService:
public class TestService:Service
{
public TestService(string aServiceName):base(aServiceName)
{}
protected override void AddRequestHandlers()
{
this.AddRequestHandler(”Test1″,new RequestHandler(Test1));
}
private void Test1(string aMessageName,IMessageItemSequence aMessageBody,ref IMessageItemSequence aReplyMessageBody)
{
aReplyMessageBody = SendRequest(”MyService”,aMessageName,aMessageBody);
aReplyMessageBody.SetValue(”result2″,”Success”);
}
}
注意在TestService中的Test1方法,它并未直接处理消息aMessageBody,而是通过调用SendRequest()方法,将其传递到MyService中。
对于客户端而言,情况比较特殊。根据前面的分析,我们知道除了发送消息的操作是在客户端完成外,其他的具体执行都在服务端实现。所以诸如MyService和TestService等服务类,只需要部署在服务端即可。而客户端则只需要定义一个实现Service的空类即可:
public class MyServiceClient:Service
{
public MyServiceClient(string aServiceName):base(aServiceName)
{}
protected override void AddRequestHandlers()
{}
}
MyServiceClient类即为客户端定义的服务类,在AddRequestHandlers()方法中并不需要实现任何代码。如果我们在Service抽象类中,将AddRequestHandlers()方法定义为virtual而非abstract方法,则这段代码在客户端服务中也可以省去。另外,客户端服务类中的aServiceName可以任意赋值,它与服务端的服务名并无实际联系。至于客户端具体会调用哪个服务,则由SendRequest()方法中的aServiceName决定:
IMessageFactory factory = new MessageFactory();
IMessageItemSequence body = factory.CreateMessageItemSequence();
//……
MyServiceClient service = new MyServiceClient(”Client”);
IMessageItemSequence reply = service.SendRequest(”TestService”,”Test1″,body);
对于service.SendRequest()的执行而言,会先调用TestService的Test1方法;然后再通过该方法向MyService发送,最终调用MyService的Test1方法。
我们还需要另外定义一个类,负责添加服务,并初始化这些服务:
public class Server
{
public Server()
{
m_Services = new ArrayList();
}
private ArrayList m_Services;
public void AddService(IListenService service)
{
this.m_Services.Add(service);
}
public void Initialize()
{
IDictionary tcpProp = new Hashtable();
tcpProp[”name”] = “tcp9090″;
tcpProp[”port”] = 9090;
TcpChannel channel = new TcpChannel(tcpProp,new BinaryClientFormatterSinkProvider(),new BinaryServerFormatterSinkProvider());
ChannelServices.RegisterChannel(channel);
foreach (Service service in m_Services)
{
service.Initialize();
}
}
}
同理,这里的Channel,IP和Port均应通过配置文件读取。最终的类图如下所示:
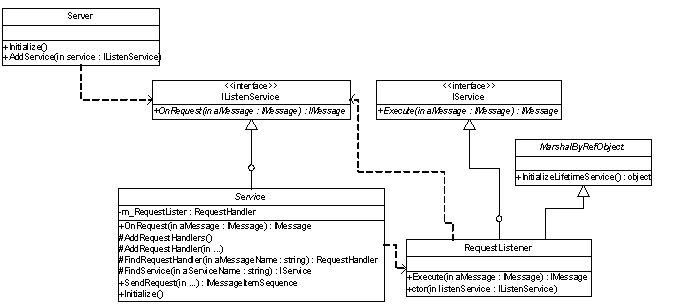
在服务端,可以调用Server类来初始化这些服务:
static void Main(string[] args)
{
MyService service = new MyService(”MyService”);
TestService service1 = new TestService(”TestService”);
Server server = new Server();
server.AddService(service);
server.AddService(service1);
server.Initialize();
Console.ReadLine();
}
四、结论
利用这个基于消息与.Net Remoting技术的分布式架构,可以将企业的业务逻辑转换为对消息的定义和处理。要增加和修改业务,就体现在对消息的修改上。服务间的通信机制则完全交给整个架构来处理。如果我们将每一个委托所实现的业务(或者消息)理解为Contract,则该结构已经具备了SOA的雏形。当然,该架构仅仅处理了消息的传递,而忽略了对底层事件的处理(类似于Corba的Event Service),这个功能我想留待后面实现。
唯一遗憾的是,我缺乏验证这个架构稳定性和效率的环境。应该说,这个架构是我们在企业项目解决方案中的一个实践。但是解决方案则是利用了CORBA中间件,在Unix环境下实现并运行。本架构仅仅是借鉴了核心的实现思想和设计理念,从而完成的在.Net平台下的移植。由于Unix与Windows Server的区别,其实际的优势还有待验证。
Comments (0)
—Next Page »
PagesAbout Me《AOP技术研究》系列《让僵冷的翅膀飞起来》系列《封装变化》系列设计之道
Blogroll
博客堂博客园Wayfarer‘s Prattlesamuel
Categories:.Net FrameworkC# Programming.Net RemotingADO.Net
Design & PatternWCFAOPPrattle
Counter: Search:
Search:
Archives:April 2006March 2006February 2006January 2006December 2005November 2005October 2005September 2005February 2005January 2005December 2004November 2004
Meta:RegisterNew PostLoginRSS 2.0Comments RSSWordPress
Powered byWordPress
_xyz
April 7, 2006
抽象的意义
Filed under:Prattle — bruce zhang @ 5:01 pm
我曾经听过一则笑话,说三个秀才到省城参加乡试。临行前三人都对自己能否中举惴惴不安,于是求教于街头的算命先生。算命老者的目光在这三人的脸上逡巡良久,最后徐徐伸出一个手指,就闭上眼睛不再言语,一付高深莫测的模样。三人纳闷,给了银子,带着疑惑到了省城参加考试。发榜之日,三人联袂去看成绩,得知结果后,三人齐叹,算命先生真乃神人矣!
三人考试的结果是什么呢?我们抛开具体的人不管,最后的结果不外乎如下几种:
1、全部高中;
2、一人高中;
3、两人高中;
4、全部落榜;
我们试想想,无论何种结果,算命先生的“一指禅”是否均为正解呢?
1、全部高中:此时“一个手指”代表“一个都不落榜”,或“一切人均高中”
2、一人高中:自然不言而喻
3、两人高中:此时“一个手指”代表“一人落榜”
4、全部落榜:此时“一个手指”代表“一个都不中”
算命先生确实高明,这“一指禅”确乎囊括了所有情况。为什么会是这样的情况,原因无它,盖因算命先生明白抽象的意义,他用一个手指抽象了四种可能。至于具体的实现,留给那三个秀才去慢慢琢磨吧。
抽象的意义有多大,看看算命先生就知道了。
Comments (0)
解决方案、项目、程序集、命名空间
Filed under:.Net Framework,C# Programming — bruce zhang @ 3:26 pm
《叩开C#之门》系列之一
前言:表弟想要学编程,我推荐他学习.Net和C#。这一推荐不打紧,我却承担上了指导的职责。我又出差在外,直接辅导是不行了,通过邮件也太麻烦。推荐了几本书,可惜他太菜了,总有无从下手的感觉。推及他人,在初学C#时,是否也有这样的感觉呢?所以,就有了这个系列文章。表弟是我把他带入计算机行业的,当初什么都不懂,我曾经打开计算机机箱,指点他哪里是硬盘、哪里是内存,是CPU,现在对于计算机硬件他早已可以做我师傅。希望学软件编程也能这样。
一、解决方案、项目、程序集、命名空间
初学者很容易把这些概念搞混淆。先说说项目(Project),通俗的说,一个项目可以就是你开发的一个软件。在.Net下,一个项目可以表现为多种类型,如控制台应用程序,Windows应用程序,类库(Class Library),Web应用程序,Web Service,Windows控件等等。如果经过编译,从扩展名来看,应用程序都会被编译为.exe文件,而其余的会被编译为.dll文件。既然是.exe文件,就表明它是可以被执行的,表现在程序中,这些应用程序都有一个主程序入口点,即方法Main()。而类库,Windows控件等,则没有这个入口点,所以也不能直接执行,而仅提供一些功能,给其他项目调用。
在Visual Studio.Net中,可以在“File”菜单中,选择“new”一个“Project”,来创建一个新的项目。例如创建控制台应用程序。注意在此时,Visual Studio除了建立了一个控制台项目之外,该项目同时还属于一个解决方案(Solution)。这个解决方案有什么用?如果你只需要开发一个Hello World的项目,解决方案自然毫无用处。但是,一个稍微复杂一点的软件,都需要很多模块来组成,为了体现彼此之间的层次关系,利于程序的复用,往往需要多个项目,每个项目实现不同的功能,最后将这些项目组合起来,就形成了一个完整的解决方案。形象地说,解决方案就是一个容器,在这个容器里,分成好多层,好多格,用来存放不同的项目。一个解决方案与项目是大于等于的关系。建立解决方案后,会建立一个扩展名为.sln的文件。
在解决方案里添加项目,不能再用“new”的方法,而是要在“File”菜单中,选择“Add Project”。添加的项目,可以是新项目,也可以是已经存在的项目。
程序集叫Assembly。学术的概念我不想提,通俗的角度来说,一个项目也就是一个程序集。从设计的角度来说,也可以看成是一个完整的模块(Module),或者称为是包(Package)。因此,一个程序集也可以体现为一个dll文件,或者exe文件。怎样划分程序集也是大有文章的,不过初学者暂时不用考虑它。
命名空间(namespace)是在C++里面就有的概念。引入它,主要是为了避免一个项目中,可能会存在的相同对象名的冲突。这个命名空间的定义,没有特殊的要求。不过基本上来说,为了保证其唯一性,最好是用uri的格式,例如BruceZhang.com。这个命名空间有点像我们姓名中的姓,然后每个对象的名字则是姓名中的名。如果有重复,在国外的命名中,还可以加上middle name。那么名都为“勇”的,由于姓氏不同也就分开了,或者叫张勇,或者叫赵勇。当然人的姓氏重复者居多,所以我们为命名空间取名时,尽可能的复杂一点。
有许多初学者,常常把一个项目就理解为一个命名空间。其实这两者没有绝对的联系,在项目里我们也可以定义很多不相同的命名空间。但为了用户便于使用,最好在一个项目中,其命名空间最好是一体的层次结构。在Visual Studio里,我们可以在项目中新建一个文件夹,默认情况下,该文件夹下对象的命名空间,应该是“项目的命名空间.文件夹名”。当然,我们也可以在namespace中修改它。
命名空间和程序集名,都可以在Visual Studio中设置。用鼠标右键单击项目名,就可以弹出如下对话框:
在图中,Assembly Name就是程序集名,如果经过编译,则为该项目的文件名。而Default Namespace则为默认的命名空间。在开发软件时,我们要养成良好的习惯,在建立新项目后,就将这些属性设置好。一旦设置好了Default Namespace,则以后新建的对象,其命名空间即为该设定的值。至于程序集名,如果是dll文件,建议其名最好与Default Namespace一致。
实例演练:
(一)创建控制台应用程序“Hello World!”
1、打开Visual Studio.Net,选择“File”菜单的“new”,选择“Project”;
2、选择Visual C# Projects中的“Console Application”,如图所示:
在Location中,定位你要保存的项目的路径,而名字则为“FirstExample”。该名字此时既是解决方案的名字,同时也是该项目的名字。
3、用鼠标右键单击项目名,在弹出的对话框中,将Assembly Name命名为HelloWorld,将Default Namespace命名为:BruceZhang.com.FirstExample。
4、此时Visual Studio中已经建立了一个文件,其名为Class1.cs(如果是Visual Studio 2005,则默认为Program.cs);修改该文件的文件名为HelloWorld.cs,同时修改文件中的namespace,和类名,如下:
namespace BruceZhang.com.FirstExample
{
///
/// Summary description for Class1.
///
class HelloWorld
{
///
/// The main entry point for the application.
///
[STAThread]
static void Main(string[] args)
{
//
// TODO: Add code to start application here
//
}
}
}
5、注意在HelloWorld.cs中,有一个Main()方法。这是因为我们建立的是控制台应用程序。在Main()方法中添加如下代码:
Console.WriteLine(”Hello World!”);
Console.Read();
这里的Console是一个能对控制台进行操作的类。
6、运行。
检查保存项目的路径文件夹FirstExample/bin/debug,已经存在了一个HelloWorld.exe文件。
(二)为解决方案添加一个新项目
1、在“File”菜单中,选择“Add Project”,添加“New Project”。在对话框中选择“Class Library”,名字为Printer。至于保存路径,可以放在之前建立的FirstExample文件夹下:
2、在Visual Studio右侧,可以看到现在有两个项目了。仍然修改新项目的名称和默认命名空间名,均为BruceZhang.com.Printer。
3、将默认建立的Class1.cs改名为MessagePrinter.cs,同时修改其代码为:
namespace BruceZhang.com.Printer
{
///
/// Summary description for Class1.
///
public class MessagePrinter
{
public MessagePrinter()
{
//
// TODO: Add constructor logic here
//
}
public static void Print(string msg)
{
Console.WriteLine(msg);
}
}
}
在MessagePrinter类中,我们注意到并没有Main()方法,因为它不是应用程序。新增加的Print()方法,能够接收一个字符串,然后在控制台中显示出来。
4、编译Printer项目。鼠标右键单击该项目名,在菜单中选择“Build”。成功编译后,找到文件夹Printer/bin/debug,可以发现有文件BruceZhang.com.Printer.dll,这就是最后形成的程序集文件。
5、关联这两个项目。我们希望是在FirstExample项目中用到Printer项目的Print()方法,前提是需要在FirstExample项目中添加对Printer项目的引用。右键单击FirstExample项目的“Reference”,选择“Add Reference”,在对话框中选择“Project”标签,找到该项目并选中,最后如图所示:
6、现在就可以在FirstExample项目中使用MessagePrinter了。首先,在命名空间中添加对它的使用(Using),然后再Main()方法中调用它,最后代码如下:
using System;
using BruceZhang.com.Printer;
namespace BruceZhang.com.FirstExample
{
///
/// Summary description for Class1.
///
class HelloWorld
{
///
/// The main entry point for the application.
///
[STAThread]
static void Main(string[] args)
{
MessagePrinter.Print(”Hello World!”);
Console.Read();
}
}
}
7、运行。结果与前一个例子一样。
在这个例子中,解决方案中就包含了两个项目,一个是控制台应用程序,一个是类库。类库提供一些基本的功能,如例子中的Print()方法。我们常常把一些共用的方法,放到类库中。这样其他的应用程序就可以去调用它。例如本例的控制台应用程序。如果新建的Windows应用程序,也需要这个功能,就可以直接引用MessagePrinter的Print()方法,而不必重复去实现。
Comments (0)
April 5, 2006
Windows Communication Foundation入门(Part One)
Filed under:WCF — bruce zhang @ 2:31 am
前言:WCF是微软基于SOA(Service Oriented Architecture)推出的.Net平台下的框架产品,它代表了软件架构设计与开发的一种发展方向,在微软的战略计划中也占有非常重要的地位。了解和掌握WCF,对于程序员特别是基于微软产品开发的程序员而言,是非常有必要的。对于WCF,笔者也是初窥门径,抱着学习的态度作这样的一个介绍。文中的内容主要参考了微软官方的文档、资料,以及众多介绍WCF的技术资料。这些资料主要都是英文,不便于国内程序员学习WCF。虽然本人才疏学浅,却愿意作这样的介绍者。由于自己仅是一个初学者,英文的功底也不够深厚,所以文中难免会有疏漏之处。同时,我也希望在文中尽量表达出自己的一些心得与见解,这就不免增加了出现错误的可能性。此外,由于WCF至今仍未有正式的版本,文中相关的技术描述以及代码会根据版本的不同而发生变化,所以我也只能尽量对此给与一定的说明。本文会是多篇文章拼凑在一起的系列,说是系列,但并没有严格的渐进关系,只是整体上希望能有一个相对全面的WCF入门介绍。此外,笔者也希望能通过此文抛砖引玉,这样也能让我的WCF学习之旅更轻松一点。
一、什么是WCF?
根据微软官方的解释,WCF(之前的版本名为“Indigo”)是使用托管代码建立和运行面向服务(Service Oriented)应用程序的统一框架。它使得开发者能够建立一个跨平台的安全、可信赖、事务性的解决方案,且能与已有系统兼容协作。WCF是微软分布式应用程序开发的集大成者,它整合了.Net平台下所有的和分布式系统有关的技术,例如.Net Remoting、ASMX、WSE和MSMQ。以通信(Communiation)范围而论,它可以跨进程、跨机器、跨子网、企业网乃至于Internet;以宿主程序而论,可以以ASP.NET,EXE,WPF,Windows Forms,NT Service,COM+作为宿主(Host)。WCF可以支持的协议包括TCP,HTTP,跨进程以及自定义,安全模式则包括SAML,Kerberos,X509,用户/密码,自定义等多种标准与模式。也就是说,在WCF框架下,开发基于SOA的分布式系统变得容易了,微软将所有与此相关的技术要素都包含在内,掌握了WCF,就相当于掌握了叩开SOA大门的钥匙。
WCF是建立在.Net Framework 2.0基础之上的,正式的版本应该会作为Windows Vista的核心部分而Release。然而,这并不代表WCF只能运行在Windows Vista下。只要安装了WinFX Runtime Components,在Windows XP和Windows 2003操作系统下,仍然可以使用。Visual Studio 2005中并没有包含WCF,但是当安装好了WinFX Runtime Components后,我们就可以在Visual Studio 2005环境下开发和创建WCF的程序了。
目前最新的WCF版本是February 2006 CTP,下载页面是:http://www.microsoft.com/downloads/details.aspx?FamilyId=F51C4D96-9AEA-474F-86D3-172BFA3B828B&displaylang=en。使用WCF需要用到一些相关的工具,如SvcUtil.exe,所以还需要下载WinFX Runtime Components的SDK,其下载页面是:http://www.microsoft.com/downloads/details.aspx?FamilyId=9BE1FC7F-0542-47F1-88DD-61E3EF88C402&displaylang=en。安装SDK可以选择网络安装或本地安装。如果是本地安装,文件大小为1.1G左右,是ISO文件。安装了SDK后,在program files目录下,有microsoft SDK目录。
WCF是微软重点介绍的产品,因此也推出了专门的官方网站(http://windowscommunication.net),该网站有最新的WCF新闻发布,以及介绍WCF的技术文档和样例代码。
二、WCF的优势
在David Chappell所撰的《Introducing Windows Communication Foundation》一文中,用了一个活鲜鲜的例子,来说明WCF的优势所在。假定我们要为一家汽车租赁公司开发一个新的应用程序,用于租车预约服务。该租车预约服务会被多种应用程序访问,包括呼叫中心(Call Center),基于J2EE的租车预约服务以及合作伙伴的应用程序(Partner Application),如图所示:
呼叫中心运行在Windows平台下,是在.Net Framework下开发的应用程序,用户为公司员工。由于该汽车租赁公司兼并了另外一家租赁公司,该公司原有的汽车预约服务应用程序是J2EE应用程序,运行在非Windows操作系统下。呼叫中心和已有的汽车预约应用程序都运行在Intranet环境下。合作伙伴的应用程序可能会运行在各种平台下,这些合作伙伴包括旅行社、航空公司等等,他们会通过Internet来访问汽车预约服务,实现对汽车的租用。
这样一个案例是一个典型的分布式应用系统。如果没有WCF,利用.Net现有的技术应该如何开发呢?
首先考虑呼叫中心,它和我们要开发的汽车预约服务一样,都是基于.Net Framework的应用程序。呼叫中心对于系统的性能要求较高,在这样的前提下,.Net Remoting是最佳的实现技术。它能够高性能的实现.Net与.Net之间的通信。
要实现与已有的J2EE汽车预约应用程序之间的通信,只有基于SOAP的Web Service可以实现此种目的,它保证了跨平台的通信;而合作伙伴由于是通过Internet来访问,利用ASP.Net Web Service,即ASMX,也是较为合理的选择,它保证了跨网络的通信。由于涉及到网络之间的通信,我们还要充分考虑通信的安全性,利用WSE(Web Service Enhancements)可以为ASMX提供安全的保证。
一个好的系统除了要保证访问和管理的安全,高性能,同时还要保证系统的可信赖性。因此,事务处理是企业应用必须考虑的因素,对于汽车预约服务而言,同样如此。在.Net中,Enterprise Service(COM+)提供了对事务的支持,其中还包括分布式事务(Distributed Transactions)。不过对于Enterprise Service而言,它仅支持有限的几种通信协议。
如果还要考虑到异步调用、脱机连接、断点连接等功能,我们还需要应用MSMQ(Microsoft Message Queuing),利用消息队列支持应用程序之间的消息传递。
如此看来,要建立一个好的汽车租赁预约服务系统,需要用到的.Net分布式技术,包括.Net Remoting、Web Service,COM+等五种技术,这既不利于开发者的开发,也加大了程序的维护难度和开发成本。正是因应于这样的缺陷,WCF才会在.Net 2.0中作为全新的分布式开发技术被微软强势推出,它整合了上述所属的分布式技术,成为了理想的分布式开发的解决之道。下图展示了WCF与之前的相关技术的比较:
从功能的角度来看,WCF完全可以看作是ASMX,.Net Remoting,Enterprise Service,WSE,MSMQ等技术的并集。(注:这种说法仅仅是从功能的角度。事实上WCF远非简单的并集这样简单,它是真正面向服务的产品,它已经改变了通常的开发模式。)因此,对于上述汽车预约服务系统的例子,利用WCF,就可以解决包括安全、可信赖、互操作、跨平台通信等等需求。开发者再不用去分别了解.Net Remoting,ASMX等各种技术了。
概括地说,WCF具有如下的优势:
1、统一性
前面已经叙述,WCF是对于ASMX,.Net Remoting,Enterprise Service,WSE,MSMQ等技术的整合。由于WCF完全是由托管代码编写,因此开发WCF的应用程序与开发其它的.Net应用程序没有太大的区别,我们仍然可以像创建面向对象的应用程序那样,利用WCF来创建面向服务的应用程序。
2、互操作性
由于WCF最基本的通信机制是SOAP,这就保证了系统之间的互操作性,即使是运行不同的上下文中。这种通信可以是基于.Net到.Net间的通信,如下图所示:
可以跨进程、跨机器甚至于跨平台的通信,只要支持标准的Web Service,例如J2EE应用服务器(如WebSphere,WebLogic)。应用程序可以运行在Windows操作系统下,也可以运行在其他的操作系统,如Sun Solaris,HP Unix,Linux等等。如下图所示:
3、安全与可信赖
WS-Security,WS-Trust和WS-SecureConversation均被添加到SOAP消息中,以用于用户认证,数据完整性验证,数据隐私等多种安全因素。
在SOAP的header中增加了WS-ReliableMessaging允许可信赖的端对端通信。而建立在WS-Coordination和WS-AtomicTransaction之上的基于SOAP格式交换的信息,则支持两阶段的事务提交(two-phase commit transactions)。
上述的多种WS-Policy在WCF中都给与了支持。对于Messaging而言,SOAP是Web Service的基本协议,它包含了消息头(header)和消息体(body)。在消息头中,定义了WS-Addressing用于定位SOAP消息的地址信息,同时还包含了MTOM(消息传输优化机制,Message Transmission Optimization Mechanism)。如图所示:
4、兼容性
WCF充分的考虑到了与旧有系统的兼容性。安装WCF并不会影响原有的技术如ASMX和.Net Remoting。即使对于WCF和ASMX而言,虽然两者都使用了SOAP,但基于WCF开发的应用程序,仍然可以直接与ASMX进行交互。
< 未完待续>
注:本部分内容主要来源于David Chappell,《Introducing Windows Communication Foundation》
Comments (0)
March 22, 2006
你注意到了吗?
Filed under:Prattle — bruce zhang @ 6:05 pm
Google提供的语言工具其实是一个好东东,用来当作辞典是绰绰有余,它还支持多种语言,真是一份免费的晚餐。
不过,你注意到了吗?如果你要利用Google的语言工具将“百度”翻译成英文,你得到的结果是“Lower”。面对搜索引擎尤其是中文的搜索引擎中最强有力的竞争对手,Google难道已经失去应有的恢宏的气度,对其竞争对手开始故意的嘲讽和贬低?也许是Google中天才们一时兴起的玩笑之作,但在我的眼中看来,却未免有失厚道了。
不要说这是百度的正宗英译,我相信从美国回来的李彦宏不会给自己公司取这样的英文名。也许是Google的老外们并不理解“百度”这两个字的含义,其实是那么的充满诗意,“众里寻她千百度,蓦然回首,那人却在灯火阑珊处。”
Comments (0)
March 6, 2006
封装变化(Part Three)
Filed under:Design & Pattern — bruce zhang @ 6:35 pm
设想这样一个需求,我们需要为自己的框架提供一个负责排序的组件。目前需要实现的是冒泡排序算法和快速排序算法,根据“面向接口编程”的思想,我们可以为这些排序算法提供一个统一的接口ISort,在这个接口中有一个方法Sort(),它能接受一个object数组参数。对数组进行排序后,返回该数组。接口的定义如下:
public interface ISort
{
void Sort(ref object[] beSorted);
}
其类图如下:
然而一般对于排序而言,排列是有顺序之分的,例如升序,或者降序,返回的结果也不相同。最简单的方法我们可以利用if语句来实现这一目的,例如在QuickSort类中:
public class QuickSort:ISort
{
private string m_SortType;
public QuickSort(string sortType)
{
m_SortType = sortType;
}
public void Sort(ref object[] beSorted)
{
if (m_SortType.ToUpper().Trim() == “ASCENDING”)
{
//执行升序的快速排序;
}
else
{
//执行降序的快速排序;
}
}
}
当然,我们也可以将string类型的SortType定义为枚举类型,减少出现错误的可能性。然而仔细阅读代码,我们可以发现这样的代码是非常僵化的,一旦需要扩展,如果要求我们增加新的排序顺序,例如字典顺序,那么我们面临的工作会非常繁重。也就是说,变化产生了。通过分析,我们发现所谓排序的顺序,恰恰是排序算法中最关键的一环,它决定了谁排列在前,谁排列在后。然而它并不属于排序算法,而是一种比较的策略,后者说是比较的行为。
如果仔细分析实现ISort接口的类,例如QuickSort类,它在实现排序算法的时候,需要对两个对象作比较。按照重构的做法,实质上我们可以在Sort方法中抽取出一个私有方法Compare(),通过返回的布尔值,决定哪个对象在前,哪个对象在后。显然,可能发生变化的是这个比较行为,利用“封装抽象”的原理,就应该为该行为建立一个专有的接口ICompare,然而分别定义实现升序、降序或者字典排序的类对象。
我们在每一个实现了ISort接口的类构造函数中,引入ICompare接口对象,从而建立起排序算法与比较算法的弱耦合关系(因为这个关系与抽象的ICompare接口相关),例如QuickSort类:
public class QuickSort:ISort
{
private ICompare m_Compare;
public QuickSort(ICompare compare)
{
m_Compare= compare;
}
public void Sort(ref object[] beSorted)
{
//实现略
for (int i = 0; i < beSorted.Length - 1; i++)
{
if (m_Compare.Compare(beSorted[i],beSorted[i+1))
{
//略;
}
}
//实现略
}
}
最后的类图如下:
通过对比较策略的封装,以应对它的变化,显然是Stategy模式的设计。事实上,这里的排序算法也可能是变化的,例如实现二叉树排序。由于我们已经引入了“面向接口编程”的思想,我们完全可以轻易的添加一个新的类BinaryTreeSort,来实现ISort接口。对于调用方而言,ISort接口的实现,同样是一个Strategy模式。此时的类结构,完全是一个对扩展开发的状态,它完全能够适应类库调用者新需求的变化。
再以PetShop为例,在这个项目中涉及到订单的管理,例如插入订单。考虑到访问量的关系,PetShop为订单管理提供了同步和异步的方式。显然,在实际应用中只能使用这两种方式的其中一种,并由具体的应用环境所决定。那么为了应对这样一种可能会很频繁的变化,我们仍然需要利用“封装变化”的原理,建立抽象级别的对象,也就是IOrderStrategy接口:
public interface IOrderStrategy
{
void Insert(PetShop.Model.OrderInfo order);
}
然后定义两个类OrderSynchronous和OrderAsynchronous。类结构如下:
在PetShop中,由于用户随时都可能会改变插入订单的策略,因此对于业务层的订单领域对象而言,不能与具体的订单策略对象产生耦合关系。也就是说,在领域对象Order类中,不能new一个具体的订单策略对象,如下面的代码:
IOrderStrategy orderInsertStrategy = new OrderSynchronous();
在Martin Fowler的文章《IoC容器和Dependency Injection模式》中,提出了解决这类问题的办法,他称之为依赖注入。不过由于PetShop并没有使用诸如Sping.Net等IoC容器,因此解决依赖问题,通常是利用配置文件结合反射来完成的。在领域对象Order类中,是这样实现的:
public class Order
{
private static readonly IOrderStategy orderInsertStrategy = LoadInsertStrategy();
private static IOrderStrategy LoadInsertStrategy()
{
// Look up which strategy to use from config file
string path = ConfigurationManager.AppSettings[”OrderStrategyAssembly”];
string className = ConfigurationManager.AppSettings[”OrderStrategyClass”];
// Load the appropriate assembly and class
return (IOrderStrategy)Assembly.Load(path).CreateInstance(className);
}
}
在配置文件web.config中,配置如下的Section:
这其实是一种折中的Service Locator模式。将定位并创建依赖对象的逻辑直接放到对象中,在PetShop的例子中,不失为一种好方法。毕竟在这个例子中,需要依赖注入的对象并不太多。但我们也可以认为是一种无奈的妥协的办法,一旦这种依赖注入的逻辑增多,为给程序者带来一定的麻烦,这时就需要一个专门的轻量级IoC容器了。
写到这里,似乎已经脱离了“封装变化”的主题。但事实上我们需要明白,利用抽象的方式封装变化,固然是应对需求变化的王道,但它也仅仅能解除调用者与被调用者相对的耦合关系,只要还涉及到具体对象的创建,即使引入了工厂模式,但具体的工厂对象的创建仍然是必不可少的。那么,对于这样一些业已被封装变化的对象,我们还应该充分利用“依赖注入”的方式来彻底解除两者之间的耦合。
Comments (0)
February 6, 2006
封装变化(Part Two)
Filed under:Design & Pattern — bruce zhang @ 8:16 pm
考虑一个日志记录工具。目前需要提供一个方便的日志,使得客户可以轻松地完成日志的记录。该日志要求被记录到指定的文本文件中,记录的内容属于字符串类型,其值由客户提供。我们可以非常容易地定义一个日志对象:
public class Log
{
public void Write(string target, string log)
{
//实现内容;
}
}
当客户需要调用日志的功能时,可以创建日志对象,完成日志的记录:
Log log = new Log();
log.Write(“error.log”, “log”);
然而随着日志记录的频繁使用,有关日志的文件越来越多,日志的查询与管理也变得越不方便。此时,客户提出,需要改变日志的记录方式,将日志内容写入到指定的数据表中。显然,如果仍然按照前面的设计,具有较大的局限性。
现在我们回到设计之初,想象一下对于日志API的设计,需要考虑到这样的变化吗?这里存在两种设计理念,即渐进的设计和计划的设计。从本例来分析,要求设计者在设计初就考虑到日志记录方式在未来的可能变化,并不容易。再者,如果在最开始就考虑全面的设计,会产生设计上的冗余。因此,采用计划的设计固然具有一定的前瞻性,但一方面对设计者的要求过高,同时也会产生一些缺陷。那么,采用渐进的设计时,遇到需求变化时,利用重构的方法,改进现有的设计,又需要考虑未来的再一次变化吗?这是一个见仁见智的问题。对于本例而言,我们完全可以直接修改Write()方法,接受一个类型判断的参数,从而解决此问题。但这样的设计,自然要担负因为未来可能的再一次变化,而导致代码大量修改的危险,例如,我们要求日志记录到指定的Xml文件中。
所以,变化是完全可能的。在时间和技术能力允许的情况下,我更倾向于将变化对设计带来的影响降低到最低。此时,我们需要封装变化。
在封装变化之前,我们需要弄清楚究竟是什么发生了变化?从需求看,是日志记录的方式发生了变化。从这个概念分析,可能会导致两种不同的结果。一种情形是,我们将日志记录的方式视为一种行为,确切的说,是用户的一种请求。另一种情形则从对象的角度来分析,我们将各种方式的日志看作不同的对象,它们调用接口相同的行为,区别仅在于创建的是不同的对象。前者需要我们封装“用户请求的变化”,而后者需要我们封装“日志对象创建的变化”。
封装“用户请求的变化”,在这里就是封装日志记录可能的变化。也就是说,我们需要把日志记录行为抽象为一个单独的接口,然后才分别定义不同的实现。如图一所示:
图一:封装日志记录行为的变化
如果熟悉设计模式,可以看到图一所表示的结构正是Command模式的体现。由于我们对日志记录行为进行了接口抽象,用户就可以自由地扩展日志记录的方式,只需要实现ILog接口即可。至于Log对象,则存在与ILog接口的弱依赖关系:
public class Log
{
private ILog log;
public Log(ILog log)
{
this.log = log;
}
public void Write(string target, string logValue)
{
log.Execute(target, logValue);
}
}
我们也可以通过封装“日志对象创建的变化”实现日志API的可扩展性。在这种情况下,日志会根据记录方式的不同,被定义为不同的对象。当我们需要记录日志时,就创建相应的日志对象,然后调用该对象的Write()方法,实现日志的记录。此时,可能会发生变化的是需要创建的日志对象,那么要封装这种变化,就可以定义一个抽象的工厂类,专门负责日志对象的创建,如图二所示:
图二:封装日志对象创建的变化
图二是Factory Method模式的体现,由抽象类LogFactory专门负责Log对象的创建。如果用户需要记录相应的日志,例如要求日志记录到数据库,需要先创建具体的LogFactory对象:
LogFactory factory = new DBLogFactory();
当在应用程序中,需要记录日志,那么再通过LogFactory对象来获取新的Log对象:
Log log = factory.Create();
log.Write(“ErrorLog”, “log”);
如果用户需要改变日志记录的方式为文本文件时,仅需要修改LogFactory对象的创建即可:
LogFactory factory = new TxtFileLogFactory();
为了更好地理解“封装对象创建的变化”,我们再来看一个例子。假如,我们需要设计一个数据库组件,它能够访问微软的Sql Server数据库。根据ADO.Net的知识,我们需要使用如下的对象:
SqlConnection, SqlCommand, SqlDataAdapter等。
如果仅就Sql Server而言,在访问数据库时,我们可以直接创建这些对象:
SqlConnection connection = new SqlConnection(strConnection);
SqlCommand command = new SqlCommand(connection);
SqlDataAdapter adapter = new SqlDataAdapter();
在一个数据库组件中,充斥着如上的语句,显然是不合理的。它充满了僵化的坏味道,一旦要求支持其他数据库时,原有的设计就需要彻底的修改,这为扩展带来了困难。
那么我们来思考一下,以上的设计应该做怎样的修改?假定该数据库组件要求或者将来要求支持多种数据库,那么对于Connection,Command,DataAdapter等对象而言,就不能具体化为Sql Server的对象。也就是说,我们需要为这些对象建立一个继承的层次结构,为他们分别建立抽象的父类,或者接口。然后针对不同的数据库,定义不同的具体类,这些具体类又都继承或实现各自的父类,例如Connection对象:
图三:Connection对象的层次结构
我为Connection对象抽象了一个统一的IConnection接口,而支持各种数据库的Connection对象都实现了IConnection接口。同样的,Command对象和DataAdapter对象也采用了相似的结构。现在,我们要创建对象的时候,可以利用多态的原理创建:
IConnection connection = new SqlConnection(strConnection);
从这个结构可以看到,根据访问的数据库的不同,对象的创建可能会发生变化。也就是说,我们需要设计的数据库组件,以现在的结构来看,仍然存在无法应对对象创建发生变化的问题。利用“封装变化”的原理,我们有必要把创建对象的责任单独抽象出来,以进行有效地封装。例如,如上的创建对象的代码,就应该由专门的对象来负责。我们仍然可以建立一个专门的抽象工厂类DBFactory,并由它负责创建Connection,Command,DataAdapter对象。至于实现该抽象类的具体类,则与目标对象的结构相同,根据数据库类型的不同,定义不同的工厂类,类图如图四所示:
图四:DBFactory的类图
图四是一个典型的Abstract Factory模式的体现。类DBFactory中的各个方法均为abstract方法,所以我们也可以用接口来代替该类的定义。继承DBFactory类的各个具体类,则创建相对应的数据库类型的对象。以SqlDBFactory类为例,创建各自对象的代码如下:
public class SqlDBFactory: DBFactory
{
public override IConnection CreateConnection(string strConnection)
{
return new SqlConnection(strConnection);
}
public override ICommand CreateCommand(IConnection connection)
{
return new SqlCommand(connection);
}
public override IDataAdapter CreateDataAdapter()
{
return new SqlDataAdapter();
}
}
现在要创建访问Sql Server数据库的相关对象,就可以利用工厂类来获得。首先,我们可以在程序的初始化部分创建工厂对象:
DBFactory factory = new SqlDBFactory();
然后利用该工厂对象创建相应的Connection,Command等对象:
IConnection connection = factory.CreateConnection(strConnection);
ICommand command = factory.CreateCommand(connection);
由于我们利用了封装变化的原理,建立了专门的工厂类,以封装对象创建的变化。可以看到,当我们引入工厂类后,Connection,Command等对象的创建语句中,已经成功地消除了其与具体的数据库类型相依赖的关系。在如上的代码中,并未出现Sql之类的具体类型,如SqlConnection、SqlCommand等。也就是说,现在创建对象的方式是完全抽象的,是与具体实现无关的。无论是访问何种数据库,都与这几行代码无关。至于涉及到的数据库类型的变化,则全部抽象到DBFactory抽象类中了。需要更改访问数据库的类型,我们也只需要修改创建工厂对象的那一行代码,例如将Sql Server类型修改为Oracle类型:
DBFactory factory = new OracleDBFactory();
很显然,这样的方式提高了数据库组件的可扩展性。我们将可能发生变化的部分封装起来,放到程序固定的部分,例如初始化部分,或者作为全局变量,更可以将这些可能发生变化的地方,放到配置文件中,通过读取配置文件的值,创建相对应的对象。如此一来,不需要修改代码,也不需要重新编译,仅仅是修改xml文件,就能实现数据库类型的改变。例如,我们创建如下的配置文件:
创建工厂对象的代码则相应修改如下:
string factoryName = ConfigurationSettings.AppSettings[“db”].ToString();
//DBLib为数据库组件的程序集:
DBFactory factory = (DBFactory)Activator.CreateInstance(“DBLib”,factoryName).Unwrap();
为数据库组件的程序集:当我们需要将访问的数据库类型修改为Oracle数据库时,只需要将配置文件中的Value值修改为“OracleDBFactory”即可。这种结构具有很好的可扩展性,较好地解决了未来可能发生的需求变化所带来的问题。
Comments (0)
January 19, 2006
封装变化(Part One)
Filed under:Design & Pattern — bruce zhang @ 8:16 pm
软件设计最大的敌人,就是应付需求不断的变化。变化有时候是无穷尽的,于是项目开发就在反复的修改、更新中无限期地延迟交付的日期。变化如悬在头顶的达摩克斯之剑,令许多软件工程专家一筹莫展。正如无法找到解决软件开发的“银弹”,要彻底将变化扼杀在摇篮之中,看来也是不可能完成的任务。那么,积极地面对“变化”,方才是可取的态度。于是,极限编程(XP)的倡导者与布道者Kent Beck提出要“拥抱变化”,从软件工程方法的角度,提出了应对“变化”的解决方案。而本文则试图从软件设计方法的角度,来探讨如何在软件设计过程中,解决未来可能的变化,其方法就是——封装变化。
设计模式是“封装变化”方法的最佳阐释。无论是创建型模式、结构型模式还是行为型模式,归根结底都是寻找软件中可能存在的“变化”,然后利用抽象的方式对这些变化进行封装。由于抽象没有具体的实现,就代表了一种无限的可能性,使得其扩展成为了可能。所以,我们在设计之初,除了要实现需求所设定的用例之外,还需要标定可能或已经存在的“变化”之处。封装变化,最重要的一点就是发现变化,或者说是寻找变化。
GOF对设计模式的分类,已经彰显了“封装变化”的内涵与精髓。创建型模式的目的就是封装对象创建的变化。例如Factory Method模式和Abstract Factory模式,建立了专门的抽象的工厂类,以此来封装未来对象的创建所引起的可能变化。而Builder模式则是对对象内部的创建进行封装,由于细节对抽象的可替换性,使得将来面对对象内部创建方式的变化,可以灵活的进行扩展或替换。
至于结构型模式,它关注的是对象之间组合的方式。本质上说,如果对象结构可能存在变化,主要在于其依赖关系的改变。当然对于结构型模式来说,处理变化的方式不仅仅是封装与抽象那么简单,还要合理地利用继承与聚合的方法,灵活地表达对象之间的依赖关系。例如Decorator模式,描述的就是对象间可能存在的多种组合方式,这种组合方式是一种装饰者与被装饰者之间的关系,因此封装这种组合方式,抽象出专门的装饰对象显然正是“封装变化”的体现。同样地,Bridge模式封装的则是对象实现的依赖关系,而Composite模式所要解决的则是对象间存在的递归关系。
行为型模式关注的是对象的行为。行为型模式需要做的是对变化的行为进行抽象,通过封装以达到整个架构的可扩展性。例如策略模式,就是将可能存在变化的策略或算法抽象为一个独立的接口或抽象类,以实现策略扩展的目的。Command模式、State模式、Vistor模式、Iterator模式概莫如是。或者封装一个请求(Command模式),或者封装一种状态(State模式),或者封装“访问”的方式(Visitor模式),或者封装“遍历”算法(Iterator模式)。而这些所要封装的行为,恰恰是软件架构中最不稳定的部分,其扩展的可能性也最大。将这些行为封装起来,利用抽象的特性,就提供了扩展的可能。
利用设计模式,通过封装变化的方法,可以最大限度的保证软件的可扩展性。面对纷繁复杂的需求变化,虽然不可能完全解决因为变化带来的可怕梦魇,然而,如能在设计之初预见某些变化,仍有可能在一定程度上避免未来存在的变化为软件架构带来的灾难性伤害。从此点看,虽然没有“银弹”,但从软件设计方法的角度来看,设计模式也是一枚不错的“铜弹”了。
Comments (0)
December 16, 2005
Switch语句,僵化的毒药
Filed under:Design & Pattern — bruce zhang @ 9:29 pm
在《Head First Design Patterns》一书中,用了大量的代码实例来讲解设计模式。该书的代码是用Java写的,Mark McFadden将其改作了C#版本的代码,下载地址:HeadFirstDesignPatternCSharp。在书中讲解Abstract Factory模式时,用PizzaStore来举例说明。这个例子非常生动,也有利于读者对Abstract Factory的理解。其中,PizzaStore的类图结构如下:
继承PizzaStore抽象类的子类NYPizzaStore和ChicagoPizzStore各自override了CreatePizza()方法,根据传入的字符串type,创建不同类型的Pizza。该方法在基类PizzaStore中被OrderPizza()方法调用。OrderPizza()方法的代码如下:
public Pizza OrderPizza(string type)
{
Pizza pizza;
pizza = CreatePizza(type);
pizza.Prepare();
pizza.Bake();
pizza.Cut();
pizza.Box();
return pizza;
}
CreatePizza()方法为虚方法,在子类NYPizzaStore中,override该方法如下:
protected override Pizza CreatePizza(string type)
{
Pizza pizza = null;
IPizzaIngredientFactory ingredientFactory = new NYPizzaIngredientFactory();
switch (type)
{
case “cheese”:
pizza = new CheesePizza(ingredientFactory);
pizza.Name = “New York Style Cheese Pizza”;
break;
case “clam”:
pizza = new ClamPizza(ingredientFactory);
pizza.Name = “New York Style Clam Pizza”;
break;
case “pepperoni”:
pizza = new PepperoniPizza(ingredientFactory);
pizza.Name = “New York Style Pepperoni Pizza”;
break;
}
return pizza;
}
然而在该方法中,却出现了讨厌的switch语句。switch语句虽然在条件判断中会被经常用到,但在本例中却不利于程序的扩展。例如增加一种Pizza,就必须修改各个PizzaStore的子类。毫无疑问,是switch语句导致了最终整个程序的僵化。那么,如何消除switch语句呢?仔细分析程序的结构,Pizza根据类型而分为CheesePizza, ClamPizza, PepperoniPizza,同时又根据PizzaStore的不同分为New York和Chicago的Pizza。这是一种类型的组合,如何对每种类型都创建一个类,这样需要定义的类对象太多。作者在解决这个问题时,是在各种类型的Pizza类的构造函数中,引入了IPizzaIngredientFactory,该工厂负责Pizza各种配料的制作(PizzaStore的不同,主要是有这些配料的制作方式不一样),这种方式将Factory模式和Bridge模式结合,保证了程序的可扩展。
在CreatePizza方法中,既然是根据type来创建不同的Pizza,也就说这个方法的责任就是用来创建Pizza的。那么,我们完全可以为程序再引入一个工厂类PizzaFactory(也可以用接口),用它来专门负责各种Pizza的创建,类图如下:
在这些创建Pizza的方法中,还需要引入IPizzaIngredientFactory对象,以决定Pizza是New York Style,还是Chicago Style。代码如下:
public abstract class PizzaFactory
{
public abstract Pizza CreatePizza(IPizzaIngredientFactory ingredientFactory);
}
public class CheesePizzaFactory : PizzaFactory
{
public override Pizza CreatePizza(IPizzaIngredientFactory ingredientFactory)
{
return new CheesePizza(ingredientFactory);
}
}
在引入该工厂类后,我们就可以对NYPizzaStore和ChicagoPizzaStore类的CreatePizza()方法做如下的修改:
public class NYPizzaStore : PizzaStore
{
protected override Pizza CreatePizza(PizzaFactory pizzaFactory)
{
IPizzaIngredientFactory ingredientFactory = new NYPizzaIngredientFactory();
return pizzaFactory.CreatePizza(ingredientFactory);
}
}
public class ChicagoPizzaStore : PizzaStore
{
protected override Pizza CreatePizza(PizzaFactory pizzaFactory)
{
IPizzaIngredientFactory ingredientFactory = new ChicagoPizzaIngredientFactory();
return pizzaFactory.CreatePizza(ingredientFactory);
}
}
在引入该工厂后,不仅消除了讨厌的switch语句,同时也使得CreatePizza()方法更加简单。要Create不同的Pizza,只需要将不同Pizza的Factory对象传递给CreatePizza()方法就可以了。相应的, PizzaStore抽象类的OrderPizza()方法中的string类型参数,也需要修改为PizzaFactory类型:
public Pizza OrderPizza(PizzaFactory pizzaFactory)
{
Pizza pizza;
pizza = CreatePizza(pizzaFactory);
pizza.Prepare();
pizza.Bake();
pizza.Cut();
pizza.Box();
return pizza;
}
当我们增加新类型的Pizza时,仅需要在PizzaFactory中增加相应的Factory类,而PizzaStore的所有子类,都不需要做任何修改。显然这种做法,更有利于程序的扩展。
Comments (0)
November 16, 2005
面向对象思想
Filed under:Design & Pattern — bruce zhang @ 10:01 pm
面向对象思想为软件设计与开发赋予了哲学的意义。在哲学的世界里,小至沙粒微尘,大至日月星辰乃至宇宙,均可视为单独的个体对象而存在。如果以哲学的目光凝视程序的世界,又何尝不是如此?一个用户,一种销售策略,一条消息,或是某种算法,一个Web的网页,面向对象思想均将其看作为一种对象。而每一种对象,都有其单独的生命周期,谁来创建它,谁来销毁它,它的内在属性,表现行为,以及它与外界之间的关系和集合,无不具有某种哲学的意味。我们在定义对象时,就好比是在描述一个活生生的事物,需要定义该对象的自然属性和社会属性,限定它的内涵与外延,勾勒出该对象的社会关系。而对于抽象、多态与封装,则是一种形而上学的概念,它将面向对象技术推向为思想的境界。
因此,我们在运用面向对象思想来定义对象时,就必须从思想的高度上俯瞰它,同时又必须结合现实来描述它。两者之间并没有绝对的矛盾。
所谓思想的高度,就要求我们必须理解所谓面向对象思想的精髓,并通过运用诸如设计模式、对象法则等知识,并从软件架构的角度出发,高屋建瓴地勾勒出整个软件结构的全貌。说得玄一些,就颇有几分“超然物外”的感觉。
所谓结合现实,也即是说对象离不开其依存的环境,毕竟软件设计不可能达到完全抽象的境界。从软件工程的角度来看,就是在设计时,需结合客户的需求、具体的业务来综合考虑。怎么界定对象的边界?对象的属性和行为是什么?哪些需要封装,而哪一些又需要暴露接口?有时候,业务才能决定设计的一切,如果纯为设计而设计,只能是空中楼阁,并不能搭建出扎实的建筑来。
Comments (0)
基于消息与.Net Remoting的分布式处理架构
Filed under:.Net Framework,Design & Pattern,.Net Remoting — bruce zhang @ 9:45 pm
分布式处理在大型企业应用系统中,最大的优势是将负载分布。通过多台服务器处理多个任务,以优化整个系统的处理能力和运行效率。分布式处理的技术核心是完成服务与服务之间、服务端与客户端之间的通信。在.Net 1.1中,可以利用Web Service或者.Net Remoting来实现服务进程之间的通信。本文将介绍一种基于消息的分布式处理架构,利用了.Net Remoting技术,并参考了CORBA Naming Service的处理方式,且定义了一套消息体制,来实现分布式处理。
示例代码:ServiceManager.rar
一、消息的定义
要实现进程间的通信,则通信内容的载体——消息,就必须在服务两端具有统一的消息标准定义。从通信的角度来看,消息可以分为两类:Request Messge和Reply Message。为简便起见,这两类消息可以采用同样的结构。
消息的主体包括ID,Name和Body,我们可以定义如下的接口方法,来获得消息主体的相关属性:
public interface IMessage:ICloneable
{
IMessageItemSequence GetMessageBody();
string GetMessageID();
string GetMessageName();
void SetMessageBody(IMessageItemSequence aMessageBody);
void SetMessageID(string aID);
void SetMessageName(string aName);
}
消息主体类Message实现了IMessage接口。在该类中,消息体Body为IMessageItemSequence类型。这个类型用于Get和Set消息的内容:Value和Item:
public interface IMessageItemSequence:ICloneable
{
IMessageItem GetItem(string aName);
void SetItem(string aName,IMessageItem aMessageItem);
string GetValue(string aName);
void SetValue(string aName,string aValue);
}
Value为string类型,并利用HashTable来存储Key和Value的键值对。而Item则为IMessageItem类型,同样的在IMessageItemSequence的实现类中,利用HashTable存储了Key和Item的键值对。
IMessageItem支持了消息体的嵌套。它包含了两部分:SubValue和SubItem。实现的方式和IMessageItemSequence相似。定义这样的嵌套结构,使得消息的扩展成为可能。一般的结构如下:
IMessage——Name
——ID
——Body(IMessageItemSequence)
——Value
——Item(IMessageItem)
——SubValue
——SubItem(IMessageItem)
——……
各个消息对象之间的关系如下:
在实现服务进程通信之前,我们必须定义好各个服务或各个业务的消息格式。通过消息体的方法在服务的一端设置消息的值,然后发送,并在服务的另一端获得这些值。例如发送消息端定义如下的消息体:
IMessageFactory factory = new MessageFactory();
IMessageItemSequence body = factory.CreateMessageItemSequence();
body.SetValue(”name1″,”value1″);
body.SetValue(”name2″,”value2″);
IMessageItem item = factory.CreateMessageItem();
item.SetSubValue(”subname1″,”subvalue1″);
item.SetSubValue(”subname2″,”subvalue2″);
IMessageItem subItem1 = factory.CreateMessageItem();
subItem1.SetSubValue(”subsubname11″,”subsubvalue11″);
subItem1.SetSubValue(”subsubname12″,”subsubvalue12″);
IMessageItem subItem2 = factory.CreateMessageItem();
subItem1.SetSubValue(”subsubname21″,”subsubvalue21″);
subItem1.SetSubValue(”subsubname22″,”subsubvalue22″);
item.SetSubItem(”subitem1″,subItem1);
item.SetSubItem(”subitem2″,subItem2);
body.SetItem(”item”,item);
//Send Request Message
MyServiceClient service = new MyServiceClient(”Client”);
IMessageItemSequence reply = service.SendRequest(”TestService”,”Test1″,body);
在接收消息端就可以通过获得body的消息体内容,进行相关业务的处理。
二、.Net Remoting服务
在.Net中要实现进程间的通信,主要是应用Remoting技术。根据前面对消息的定义可知,实际上服务的实现,可以认为是对消息的处理。因此,我们可以对服务进行抽象,定义接口IService:
public interface IService
{
IMessage Execute(IMessage aMessage);
}
Execute()方法接受一条Request Message,对其进行处理后,返回一条Reply Message。在整个分布式处理架构中,可以认为所有的服务均实现该接口。但受到Remoting技术的限制,如果要实现服务,则该服务类必须继承自MarshalByRefObject,同时必须在服务端被Marshal。随着服务类的增多,必然要在服务两端都要对这些服务的信息进行管理,这加大了系统实现的难度与管理的开销。如果我们从另外一个角度来分析服务的性质,基于消息处理而言,所有服务均是对Request Message的处理。我们完全可以定义一个Request服务负责此消息的处理。
然而,Request服务处理消息的方式虽然一致,但毕竟服务实现的业务,即对消息处理的具体实现,却是不相同的。对我们要实现的服务,可以分为两大类:业务服务与Request服务。实现的过程为:首先,具体的业务服务向Request服务发出Request请求,Request服务侦听到该请求,然后交由其侦听的服务来具体处理。
业务服务均具有发出Request请求的能力,且这些服务均被Request服务所侦听,因此我们可以为业务服务抽象出接口IListenService:
public interface IListenService
{
IMessage OnRequest(IMessage aMessage);
}
Request服务实现了IService接口,并包含IListenService类型对象的委派,以执行OnRequest()方法:
public class RequestListener:MarshalByRefObject,IService
{
public RequestListener(IListenService listenService)
{
m_ListenService = listenService;
}
private IListenService m_ListenService;
#region IService Members
public IMessage Execute(IMessage aMessage)
{
return this.m_ListenService.OnRequest(aMessage);
}
#endregion
public override object InitializeLifetimeService()
{
return null;
}
}
在RequestListener服务中,继承了MarshalByRefObject类,同时实现了IService接口。通过该类的构造函数,接收IListService对象。
由于Request消息均由Request服务即RequestListener处理,因此,业务服务的类均应包含一个RequestListener的委派,唯一的区别是其服务名不相同。业务服务类实现IListenService接口,但不需要继承MarshalByRefObject,因为被Marshal的是该业务服务内部的RequestListener对象,而非业务服务本身:
public abstract class Service:IListenService
{
public Service(string serviceName)
{
m_ServiceName = serviceName;
m_RequestListener = new RequestListener(this);
}
#region IListenService Members
public IMessage OnRequest(IMessage aMessage)
{
//……
}
#endregion
private string m_ServiceName;
private RequestListener m_RequestListener;
}
Service类是一个抽象类,所有的业务服务均继承自该类。最后的服务架构如下:
我们还需要在Service类中定义发送Request消息的行为,通过它,才能使业务服务被RequestListener所侦听。
public IMessageItemSequence SendRequest(string aServiceName,string aMessageName,IMessageItemSequence aMessageBody)
{
IMessage message = m_Factory.CreateMessage();
message.SetMessageName(aMessageName);
message.SetMessageID(”");
message.SetMessageBody(aMessageBody);
IService service = FindService(aServiceName);
IMessageItemSequence replyBody = m_Factory.CreateMessageItemSequence();
if (service != null)
{
IMessage replyMessage = service.Execute(message);
replyBody = replyMessage.GetMessageBody();
}
else
{
replyBody.SetValue(”result”,”Failure”);
}
return replyBody;
}
注意SendRequest()方法的定义,其参数包括服务名,消息名和被发送的消息主体。而在实现中最关键的一点是FindService()方法。我们要查找的服务正是与之对应的RequestListener服务。不过,在此之前,我们还需要先将服务Marshal:
public void Initialize()
{
RemotingServices.Marshal(this.m_RequestListener,this.m_ServiceName + “.RequestListener”);
}
我们Marshal的对象,是业务服务中的Request服务对象m_RequestListener,这个对象在Service的构造函数中被实例化:
m_RequestListener = new RequestListener(this);
注意,在实例化的时候是将this作为IListenService对象传递给RequestListener。因此,此时被Marshal的服务对象,保留了业务服务本身即Service的指引。可以看出,在Service和RequestListener之间,采用了“双重委派”的机制。
通过调用Initialize()方法,初始化了一个服务对象,其类型为RequestListener(或IService),其服务名为:Service的服务名 + “.RequestListener”。而该服务正是我们在SendRequest()方法中要查找的Service:
IService service = FindService(aServiceName);
下面我们来看看FindService()方法的实现:
protected IService FindService(string aServiceName)
{
lock (this.m_Services)
{
IService service = (IService)m_Services[aServiceName];
if (service != null)
{
return service;
}
else
{
IService tmpService = GetService(aServiceName);
AddService(aServiceName,tmpService);
return tmpService;
}
}
}
可以看到,这个服务是被添加到m_Service对象中,该对象为SortedList类型,服务名为Key,IService对象为Value。如果没有找到,则通过私有方法GetService()来获得:
private IService GetService(string aServiceName)
{
IService service = (IService)Activator.GetObject(typeof(RequestListener),
“tcp://localhost:9090/” + aServiceName + “.RequestListener”);
return service;
}
在这里,Channel、IP、Port应该从配置文件中获取,为简便起见,这里直接赋为常量。
再分析SendRequest方法,在找到对应的服务后,执行了IService的Execute()方法。此时的IService为RequestListener,而从前面对RequestListener的定义可知,Execute()方法执行的其实是其侦听的业务服务的OnRequest()方法。
我们可以定义一个具体的业务服务类,来分析整个消息传递的过程。该类继承于Service抽象类:
public class MyService:Service
{
public MyService(string aServiceName):base(aServiceName)
{}
}
假设把进程分为服务端和客户端,那么对消息处理的步骤如下:
1、 在客户端调用MyService的SendRequest()方法发送Request消息;
2、 查找被Marshal的服务,即RequestListener对象,此时该对象应包含对应的业务服务对象MyService;
3、 在服务端调用RequestListener的Execute()方法。该方法则调用业务服务MyService的OnRequest()方法。
在这些步骤中,除了第一步在客户端执行外,其他的步骤均是在服务端进行。
三、业务服务对于消息的处理
前面实现的服务架构,已经较为完整地实现了分布式的服务处理。但目前的实现,并未体现对消息的处理。我认为,对消息的处理,等价与具体的业务处理。这些业务逻辑必然是在服务端完成。每个服务可能会处理单个业务,也可能会处理多个业务。并且,服务与服务之间仍然存在通信,某个服务在处理业务时,可能需要另一个服务的业务行为。也就是说,每一种类的消息,处理的方式均有所不同,而这些消息的唯一标识,则是在SendRequest()方法已经有所体现的aMessageName。
虽然,处理的消息不同,所需要的服务不同,但是根据我们对消息的定义,我们仍然可以将这些消息处理机制抽象为一个统一的格式;在.Net中,体现这种机制的莫过于委托delegate。我们可以定义这样的一个委托:
public delegate void RequestHandler(string aMessageName,IMessageItemSequence aMessageBody,ref IMessageItemSequence aReplyMessageBody);
在RequestHandler委托中,它代表了这样一族方法:接收三个入参,aMessageName,aMessageBody,aReplyMessageBody,返回值为void。其中,aMessageName代表了消息名,它是消息的唯一标识;aMessageBody是待处理消息的主体,业务所需要的所有数据都存储在aMessageBody对象中。aReplyMessageBody是一个引用对象,它存储了消息处理后的返回结果,通常情况下,我们可以用< "result","Success">或< "result", "Failure">来代表处理的结果是成功还是失败。
这些委托均在服务初始化时被添加到服务类的SortedList对象中,键值为aMessageName。所以我们可以在抽象类中定义如下方法:
protected abstract void AddRequestHandlers();
protected void AddRequestHandler(string aMessageName,RequestHandler handler)
{
lock (this.m_EventHandlers)
{
if (!this.m_EventHandlers.Contains(aMessageName))
{
this.m_EventHandlers.Add(aMessageName,handler);
}
}
}
protected RequestHandler FindRequestHandler(string aMessageName)
{
lock (this.m_EventHandlers)
{
RequestHandler handler = (RequestHandler)m_EventHandlers[aMessageName];
return handler;
}
}
AddRequestHandler()用于添加委托对象与aMessageName的键值对,而FindRequestHandler()方法用于查找该委托对象。而抽象方法AddRequestHandlers()则留给Service的子类实现,简单的实现如MyService的AddRequestHandlers()方法:
public class MyService:Service
{
public MyService(string aServiceName):base(aServiceName)
{}
protected override void AddRequestHandlers()
{
this.AddRequestHandler(”Test1″,new RequestHandler(Test1));
this.AddRequestHandler(”Test2″,new RequestHandler(Test2));
}
private void Test1(string aMessageName,IMessageItemSequence aMessageBody,ref IMessageItemSequence aReplyMessageBody)
{
Console.WriteLine(”MessageName:{0}\n”,aMessageName);
Console.WriteLine(”MessageBody:{0}\n”,aMessageBody);
aReplyMessageBody.SetValue(”result”,”Success”);
}
private void Test2(string aMessageName,IMessageItemSequence aMessageBody,ref IMessageItemSequence aReplyMessageBody)
{
Console.WriteLine(”Test2″ + aMessageBody.ToString());
}
}
Test1和Test2方法均为匹配RequestHandler委托签名的方法,然后在AddRequestHandlers()方法中,通过调用AddRequestHandler()方法将这些方法与MessageName对应起来,添加到m_EventHandlers中。
需要注意的是,本文为了简要的说明这种处理方式,所以简化了Test1和Test2方法的实现。而在实际开发中,它们才是实现具体业务的重要方法。而利用这种方式,则解除了服务之间依赖的耦合度,我们随时可以为服务添加新的业务逻辑,也可以方便的增加服务。
通过这样的设计,Service的OnRequest()方法的最终实现如下所示:
public IMessage OnRequest(IMessage aMessage)
{
string messageName = aMessage.GetMessageName();
string messageID = aMessage.GetMessageID();
IMessage message = m_Factory.CreateMessage();
IMessageItemSequence replyMessage = m_Factory.CreateMessageItemSequence();
RequestHandler handler = FindRequestHandler(messageName);
handler(messageName,aMessage.GetMessageBody(),ref replyMessage);
message.SetMessageName(messageName);
message.SetMessageID(messageID);
message.SetMessageBody(replyMessage);
return message;
}
利用这种方式,我们可以非常方便的实现服务间通信,以及客户端与服务端间的通信。例如,我们分别在服务端定义MyService(如前所示)和TestService:
public class TestService:Service
{
public TestService(string aServiceName):base(aServiceName)
{}
protected override void AddRequestHandlers()
{
this.AddRequestHandler(”Test1″,new RequestHandler(Test1));
}
private void Test1(string aMessageName,IMessageItemSequence aMessageBody,ref IMessageItemSequence aReplyMessageBody)
{
aReplyMessageBody = SendRequest(”MyService”,aMessageName,aMessageBody);
aReplyMessageBody.SetValue(”result2″,”Success”);
}
}
注意在TestService中的Test1方法,它并未直接处理消息aMessageBody,而是通过调用SendRequest()方法,将其传递到MyService中。
对于客户端而言,情况比较特殊。根据前面的分析,我们知道除了发送消息的操作是在客户端完成外,其他的具体执行都在服务端实现。所以诸如MyService和TestService等服务类,只需要部署在服务端即可。而客户端则只需要定义一个实现Service的空类即可:
public class MyServiceClient:Service
{
public MyServiceClient(string aServiceName):base(aServiceName)
{}
protected override void AddRequestHandlers()
{}
}
MyServiceClient类即为客户端定义的服务类,在AddRequestHandlers()方法中并不需要实现任何代码。如果我们在Service抽象类中,将AddRequestHandlers()方法定义为virtual而非abstract方法,则这段代码在客户端服务中也可以省去。另外,客户端服务类中的aServiceName可以任意赋值,它与服务端的服务名并无实际联系。至于客户端具体会调用哪个服务,则由SendRequest()方法中的aServiceName决定:
IMessageFactory factory = new MessageFactory();
IMessageItemSequence body = factory.CreateMessageItemSequence();
//……
MyServiceClient service = new MyServiceClient(”Client”);
IMessageItemSequence reply = service.SendRequest(”TestService”,”Test1″,body);
对于service.SendRequest()的执行而言,会先调用TestService的Test1方法;然后再通过该方法向MyService发送,最终调用MyService的Test1方法。
我们还需要另外定义一个类,负责添加服务,并初始化这些服务:
public class Server
{
public Server()
{
m_Services = new ArrayList();
}
private ArrayList m_Services;
public void AddService(IListenService service)
{
this.m_Services.Add(service);
}
public void Initialize()
{
IDictionary tcpProp = new Hashtable();
tcpProp[”name”] = “tcp9090″;
tcpProp[”port”] = 9090;
TcpChannel channel = new TcpChannel(tcpProp,new BinaryClientFormatterSinkProvider(),new BinaryServerFormatterSinkProvider());
ChannelServices.RegisterChannel(channel);
foreach (Service service in m_Services)
{
service.Initialize();
}
}
}
同理,这里的Channel,IP和Port均应通过配置文件读取。最终的类图如下所示:
在服务端,可以调用Server类来初始化这些服务:
static void Main(string[] args)
{
MyService service = new MyService(”MyService”);
TestService service1 = new TestService(”TestService”);
Server server = new Server();
server.AddService(service);
server.AddService(service1);
server.Initialize();
Console.ReadLine();
}
四、结论
利用这个基于消息与.Net Remoting技术的分布式架构,可以将企业的业务逻辑转换为对消息的定义和处理。要增加和修改业务,就体现在对消息的修改上。服务间的通信机制则完全交给整个架构来处理。如果我们将每一个委托所实现的业务(或者消息)理解为Contract,则该结构已经具备了SOA的雏形。当然,该架构仅仅处理了消息的传递,而忽略了对底层事件的处理(类似于Corba的Event Service),这个功能我想留待后面实现。
唯一遗憾的是,我缺乏验证这个架构稳定性和效率的环境。应该说,这个架构是我们在企业项目解决方案中的一个实践。但是解决方案则是利用了CORBA中间件,在Unix环境下实现并运行。本架构仅仅是借鉴了核心的实现思想和设计理念,从而完成的在.Net平台下的移植。由于Unix与Windows Server的区别,其实际的优势还有待验证。
Comments (0)
—Next Page »
PagesAbout Me《AOP技术研究》系列《让僵冷的翅膀飞起来》系列《封装变化》系列设计之道
Blogroll
博客堂博客园Wayfarer‘s Prattlesamuel
Categories:.Net FrameworkC# Programming.Net RemotingADO.Net
Design & PatternWCFAOPPrattle
Counter:
Search:Archives:April 2006March 2006February 2006January 2006December 2005November 2005October 2005September 2005February 2005January 2005December 2004November 2004
Meta:RegisterNew PostLoginRSS 2.0Comments RSSWordPress
Powered byWordPress
_xyz
Bruce Zhang写在燃情岁月
Bruce Nauman
电影《燃情岁月》观感
[江山如画]第二集:燃情岁月
zhang ting zhi biao
[转载]内存对齐_Cecil Zhang
Zhang Ziyi denies charity fraud
Zhang Ziyi denies charity fraud
nancy zhang 浮萍中的女孩子
nancy zhang 浮萍中的女孩子
张毅 > 弦情岁月
庆祝建国60周年演讲稿zhang
天使面孔惹火身材林zhang
09年宝洁申请全纪录( by vivi ZHANG)
Bruce Bueno de Mesquita用博弈论模型精确预言未来
Bruce Bueno de Mesquita用博弈论模型精确预言未来
把握技术心态 驾驭人生航船(bruce修正)
5月20日深度研究:东北板块期待燃情岁月
张毅小提琴专辑《弦情岁月》
弦情岁月【小提琴曲播放器】
那些燃烧的“基情岁月”
弦情岁月--小提琴(张毅)
写在妇女节
写在母亲节